TL;DR
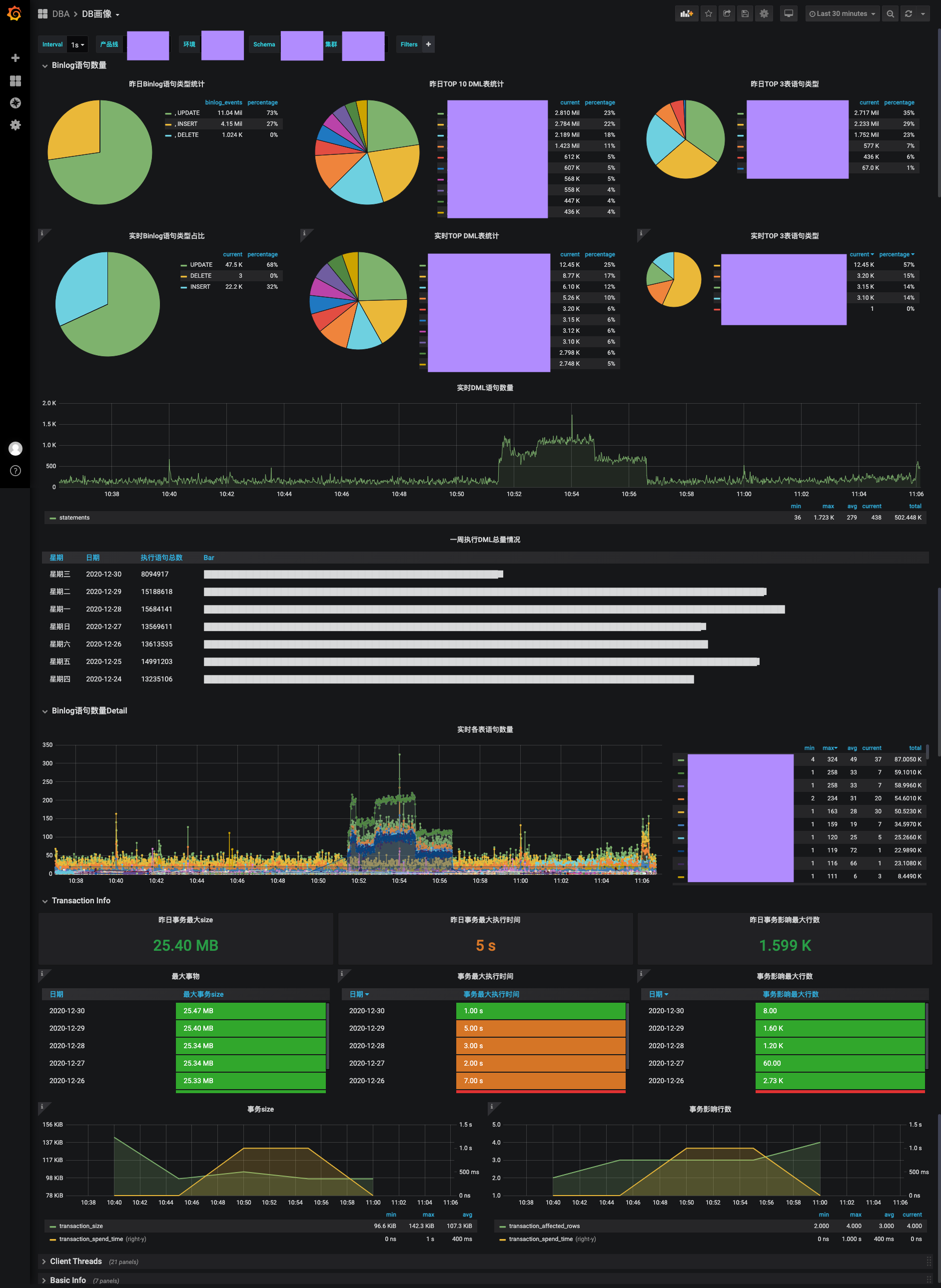
| 用例 | ping_type=CONNECT | ping_type=INSERT |
|---|---|---|
| master too many connection | 不会触发failover | 不会触发failover |
| master hang | 不会触发failover | 会触发failover且成功 |
| 仅manager无法连通master | 不会触发failover | 不会触发failover |
| manager无法连通master, 且无法ssh slave1 | 不会触发failover | 不会触发failover |
| manager无法连通master, 且无法ssh slave1和slave2 | 不会触发failover | 不会触发failover |
| manager无法连通master, ssh到slave1后无法连通master | 不会触发failover | 不会触发failover |
| manager无法连通master, ssh到slave1和slave2后均无法连通master | 会触发failover且成功 | 会触发failover且成功(长连接断开后才会) |
| master宕机前slave1也宕机了 | 会触发failover, 但failover失败 | 会触发failover, 但failover失败 |
| master挂了, 在此之前slave-1 io_thread stop了 | 会failover且成功 | 会failover且成功 |
| master挂了, 在此之前slave-1 io_thread error了 | 会failover且成功 | 会failover且成功 |
| master挂了, 在此之前slave-1 sql_thread stop了 | 会failover且成功 | 会failover且成功 |
| master挂了, 在此之前slave-1 sql_thread error了 | 会触发failover, 但failover失败 | 会触发failover, 但failover失败 |