
只讨论5.7增强半同步和双1的情况
增强半同步会不会丢数据?
这里涉及两个过程:
- 主库 Innodb与Binlog日志的2PC
- 增强半同步
Innodb与Binlog日志的2PC
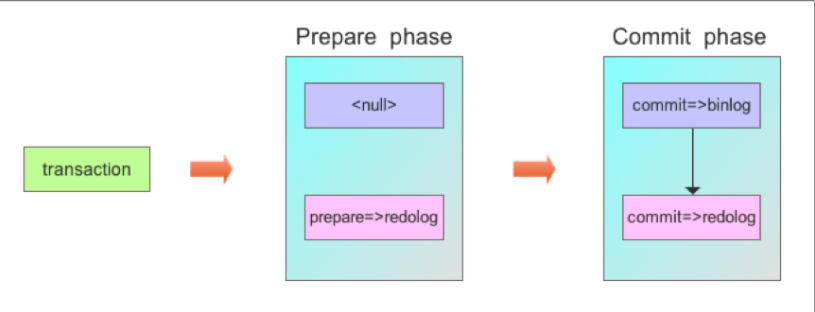
在开启Binlog后, MySQL内部会自动将普通事务当做一个XA事务来处理:
- 自动为每个事务分配一个唯一的ID
- COMMIT会被自动的分成Prepare和Commit两个阶段
- Binlog会被当做事务协调者(Transaction Coordinator), Binlog Event会被当做协调者日志
分布式事务ID(XID)
使用2PC时, MySQL会自动的为每一个事务分配一个ID, 叫XID. XID是唯一的, 每个事务的XID都不相同. XID会分别被Binlog和InnoDB记入日志中, 供恢复时使用. MySQ内部的XID由三部分组成:
- 前缀部分
前缀部分是字符串”MySQLXid” - Server ID部分
当前MySQL的server_id - query_id部分
为了保证XID的的唯一性, 数字部分使用了query_id. MySQL内部会自动的为每一个语句分配一个query_id, 全局唯一.
事务的协调者Binlog
Binlog在2PC中充当了事务的协调者(Transaction Coordinator). 由Binlog来通知InnoDB引擎来执行prepare, commit或者rollback的步骤. 事务提交的整个过程如下:
协调者准备阶段(Prepare Phase)
告诉引擎做Prepare, InnoDB更改事务状态, 并将Redo Log刷入磁盘.个人理解: innodb写prepare log, 事务标记为prepare状态, 并写入xid
协调者提交阶段(Commit Phase)
2.1 记录协调者日志, 即Binlog日志.
2.2 告诉引擎做commit.个人理解: 写Binlog event和xid, 写完后通知innodb commit, innodb写commit log, 事务标记为commit状态 (记得姜成尧说要写binlog file pos到redo)
注意:记录Binlog是在InnoDB引擎Prepare(即Redo Log写入磁盘)之后, 这点至关重要.
协调者日志Xid_log_event
作为协调者, Binlog需要将事务的XID记入日志, 供恢复时使用. Xid_log_event有以下几个特点:
仅记录query_id
因为前缀部分不变, server_id已经记录在Event Header中, Xid_log_event中只记录query_id部分.标志事务的结束
在Binlog中相当于一个事务的COMMIT语句.
一个事务在Binlog中看起来时这样的:1
2
3Query_log_event("BEGIN");
DML产生的events;
Xid_log_event;DDL没有BEGIN, 也没有Xid_log_event.
仅InnoDB的DML会产生Xid_log_event
因为MyISAM不支持2PC所以不能用Xid_log_event, 但会有COMMIT Event.
1
2
3Query_log_event("BEGIN");
DML产生的events;
Query_log_event("COMMIT");
恢复(Recovery)
这个机制是如何保证MySQL的CrashSafe的呢, 我们来分析一下. 这里我们假设用户设置了以下参数来保证可靠性:
sync_binlog=1
innodb_flush_log_at_trx_commit=1
恢复前事务的状态
在恢复开始前事务有以下几种状态:
- InnoDB中已经提交
根据前面2PC的过程, 可知Binlog中也一定记录了该事务的的Events(我感觉说的应该是Xid_log_event). 所以这种事务是一致的不需要处理. - InnoDB中是prepared状态, Binlog中有该事务的Events(我感觉说的应该是Xid_log_event).
需要通知InnoDB提交这些事务. - InnoDB中是prepared状态, Binlog中没有该事务的Events(我感觉说的应该是Xid_log_event).
因为Binlog还没记录, 需要通知InnoDB回滚这些事务. - Before InnoDB Prepare
事务可能还没执行完, 因此InnoDB中的状态还没有prepare. 根据2PC的过程, Binlog中也没有该事务的events(我感觉说的应该是Xid_log_event). 需要通知InnoDB回滚这些事务.
恢复过程
从上面的事务状态可以看出: 恢复时事务要提交还是回滚, 是由Binlog来决定的.
- 事务的Xid_log_event存在, 就要提交.
- 事务的Xid_log_event不存在, 就要回滚.
恢复的过程非常简单:
- 从Binlog中读出所有的Xid_log_event
- 告诉InnoDB提交这些XID的事务
- InnoDB回滚其它的事务
了解了MySQL关于Innodb与Binlog的两阶段提交机制后,就可以更深入去探究MySQL在故障恢复时的处理过程。 在MySQL启动时,首先会初始化存储引擎,如本例中的InnoDB引擎,然后InnoDB引擎层会读取redolog进行InnoDB层的故障恢复,回滚未prepared和commit的事务,但对于已经prepared,但未commit的事务,暂时挂起,保存到一个链表中,等待后续读取binlog日志,然后根据binlog日志再对这部分prepared的事务进行处理。 接下来,MySQL会读取最后一个binlog文件。binlog文件通常是以固定的文件名加一组连续的编号来命名的,并且将其记录到一个binlog索引文件中,因此索引文件中的最后一个binlog文件即是MySQL将要读取的最后一个binlog文件。 读取这个binlog文件时,通过文件头上是否存在标记LOG_EVENT_BINLOG_IN_USE_F,通过这个标记可以知道上次MySQL是正常关闭还是异常关闭,如果是异常关闭,则会进入故障恢复过程。 进入故障恢复过程后,会依次读取最后一个binlog文件中的所有log event,并将所有已提交事务的binlog日志中记录的xid提取出来添加到hash表中,以备后续对前述InnoDB故障恢复后遗留的Prepared事务继续处理。另外此处还要定位最后一个完整事务的位置,防止在上次系统异常关闭时有部分binlog日志未刷到磁盘上,即存在写了一半的binlog事务日志,这部分写了一半binlog日志的事务在MySQL中会按事务未提交来处理,后续会将其在存储引擎层回滚。当此文件中的内容全部读出之后,一是得到一个已提交事务的列表,另一个是最后一个完整事务的位置。 然后检查由InnoDB层得到的Prepared事务列表,若Prepared事务在从Binlog中得到的提交事务列表中,则在InnoDB层提交此事务,否则回滚此事务。
疑问1:如果事务的Binlog Event只记录了一部分怎么办?
只有最后一个事务的Event会发生这样的情况。在恢复时,binlog会自动的将这个不完整的事务Events从Binlog文件中给清除掉。
疑问2:随着长时间的运行,Binlog中会积累了很多Xid_log_event,读取所有的Xid_log_event会不会效率很低?
当然很低,所以Binlog中有一个机制来保证恢复时只用读取最后一个Binlog文件中的Xid_log_event。这种机制很像一个简单的Xid_log_event的checkpoint机制。
CrashSafe的写盘次数
前面说道要想保证CrashSafe就要设置下面两个参数为1:
sync_binlog=1
innodb_flush_log_at_trx_commit=1
下面我们来看看这两个参数的作用.
- sync_binlog
sync_binlog是控制Binlog写盘的, 1表示每次都写. 由于Binlog使用了组提交(Group Commit)的机制, 它代表一组事务提交时必须要将Binlog文件写入硬件存储1次. - innodb_flush_log_at_trx_commit的写盘次数
这个变量是用来控制InnoDB commit时写盘的方法的. 现在commit被分成了两个阶段, 到底在哪个阶段写盘, 还是两个阶段都要写盘呢? - Prepare阶段时需要写盘
2PC要求在Prepare时就要将数据持久化, 只有这样, 恢复时才能提交已经记录了Xid_log_event的事务. - Commit阶段时不需要写盘
如果Commit阶段不写盘, 会造成什么结果呢?已经Cmmit了的事务, 在恢复时的状态可能是Prepared. 由于恢复时, Prepared的事务可以通过Xid_log_event来提交事务, 所以在恢复后事务的状态就是正确的. 因此在Commit阶段不需要写盘.
总的来说保证MySQL服务的CrashSafe需要写两次盘. 在2PC的过程中, InnoDB只在prepare阶段时, 写一次盘. Binlog在commit阶段, 会设置一个参数告诉InnoDB不要写盘. 这个参数是thd->durability_property= HA_IGNORE_DURABILITY;代码在sql/binlog.cc的MYSQL_BIN_LOG::ordered_commit()中.
增强半同步
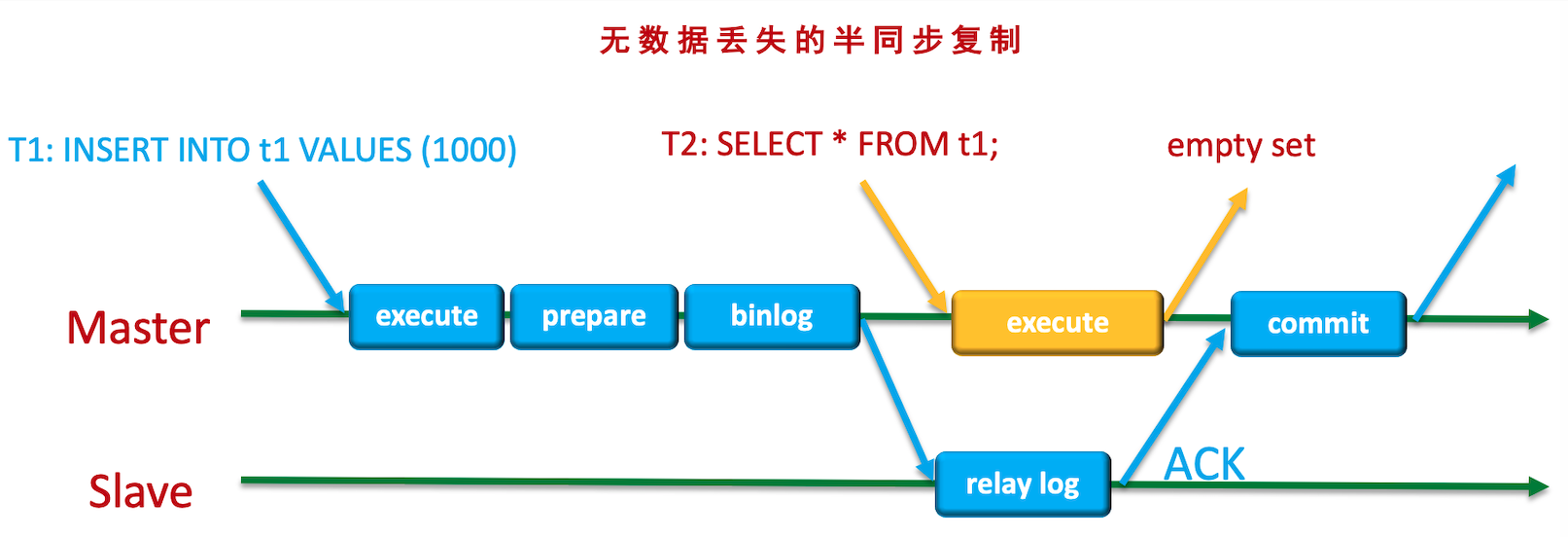
对于增强半同步, 主要有两种情况:
- 主库写binlog落盘后, Binlog dump线程发送binlog给从库, 从库IO thread接收写入relay log, 但是没有写入完, 主库挂了
- 从库IO thread成功写入relay log后, 还没发送ACK或ACK发送了但是主库收到前, 主库挂了
第一种情况
对应用来说, 并没有收到commit ok的信息, 应当认为事务提交失败.
对于主库, 因为已经写了Binlog(写了Xid_log_event), 只是还没有写commit log, crash recover后, 这部分事务又会提交掉
1 | 假设一主一从半同步 |
可以看到当前是半同步状态, 主库rpl_semi_sync_master_timeout=999999, 写入了一条数据.
我们关闭从库, 之后开三个窗口执行三个insert
1 | root@localhost 19:24:50 [dbms_monitor]> insert into semi_sync values(2, now()); |
由于rpl_semi_sync_master_wait_for_slave_count=1, 所以三个insert都在等待.
此时kill主库, 然后重启主库
1 | [root@centos-1 mysql5731]# ps -ef| grep mysqld |
查看数据
1 | root@localhost 19:26:44 [dbms_monitor]> select * from semi_sync; |
可以看到, 三个insert在crash recover后成功提交了
由此可以看出, 主库宕机恢复后是不能作为从库加入原集群的, 需要重做, 否则数据不一致.
第二种情况
对应用来说, 并没有收到commit ok的信息, 应当认为事务提交失败.
但是由于这部分事务已经写入了relay log, 从库sql thread应用完relay log中所有binlog event后提升为主库, 此时应用连接到新主库, 准备重试, 那么可能会出现问题:
对于INSERT:
如果INSERT语句中没有显式指定主键或任何唯一键, 那么应用重试插入后, 会出现重复数据.
对于UPDATE
如果采用update set amount=amount-1000 where id的方式重试, 会出现重复扣款, 所以即便重试, where条件中也应当带上要更新列的原值
对于DELETE
没什么影响, 只是影响行数为0
结论
不会丢数据.
对于MHA+增强半同步, 主从切换后, 业务不能盲目重试, 而应当做事务执行失败, 按照正常逻辑重新执行完整的事务.