
TL;DR
如果预估自己的业务数据量不大(日增不到百万行), 那么写分布式表和本地表都可以, 但要注意如果选择写本地表, 请保证每次写入数据都建立新的连接, 且每个连接写入的数据量基本相同
如果预估自己的业务数据量大(日增百万以上, 并发插入大于10), 那么请写本地表
建议每次插入50W行左右数据, 最多不可超过100W行. 总之CH不像MySQL要小事务. 比如1000W行数据, MySQL建议一次插入1W左右, 使用小事务, 执行1000次. CH建议20次,每次50W. 这是MergeTree引擎原理决定的, 频繁少量插入会导致data part过多, 合并不过来.
再有, AP不像TP, TP为了避免建立新连接产生的损耗影响性能, 通常会使用长连接, 连接池等技术做优化. 但AP业务不需要, 因为AP的属性就不会有高并发, 小SQL.
原因请继续看
看了一些文档都建议写分布式表, 虽说别人没必要骗我们, 但是搞技术的不能人云亦云, 还是要明白为啥, 说实话我想了很久没想出直接写分布式表有什么致命缺陷, 于是在ClickHouse中文社区提了问题, 内容如下
看了sina高鹏大佬的分享,看了 https://github.com/ClickHouse/ClickHouse/issues/1854 ,还看了一些文章都是建议写本地表而不是分布式表
如果我设置 internal_replication=true , 使用 ReplicatedMergeTree 引擎, 除了写本地表更灵活可控外, 写分布式表到底有什么致命缺陷吗?
因为要给同事解释, 只说一个大家说最佳实践是这样是不行的.. 我自己也没理解到底写分布式表有啥大缺陷
如果说造成数据分布不均匀, sharding key 我设为 rand() 还会有很大不均匀吗? 如果说扩容, 我也可以通过调整 weight 控制数据尽量写入新 shared 啊?
难道是因为:
Data is written asynchronously. When inserted in the table, the data block is just written to the local file system. The data is sent to the remote servers in the background as soon as possible. The period for sending data is managed by the distributed_directory_monitor_sleep_time_ms and distributed_directory_monitor_max_sleep_time_ms settings. The Distributed engine sends each file with inserted data separately, but you can enable batch sending of files with the distributed_directory_monitor_batch_inserts setting. This setting improves cluster performance by better utilizing local server and network resources. You should check whether data is sent successfully by checking the list of files (data waiting to be sent) in the table directory: /var/lib/clickhouse/data/database/table/.
>
If the server ceased to exist or had a rough restart (for example, after a device failure) after an INSERT to a Distributed table, the inserted data might be lost. If a damaged data part is detected in the table directory, it is transferred to the ‘broken’ subdirectory and no longer used.
上面文档内容我理解意思是说假如我有S1 S2 S3 三个节点,每个节点都有local表和分布式表. 我向S1的分布式表写数据1, 2, 3,
1写入S1, 2,3先写到S1本地文件系统, 然后异步发送到S2 S3 , 比如2发给S2, 3发给S3, 如果此时S3宕机了, 则3发到S3失败, 但是1,2还是成功写到S1,S2了? 所以整个过程不能保证原子性? 出现问题还要人为修数据?
https://github.com/ClickHouse/ClickHouse/issues/1343 这个issue说S3 come back后S1会尝试重新发送数据给S3.
Data blocks are written in /var/lib/clickhouse/data/database/table/ folder. Special thread checks directory periodically and tries to send data. If it can’t, it will try next time.
那么只剩文档最后一句意思是如果S1过程中宕机, 会丢数据?
自问自答一下吧, weight 是分片级别的, 不是表级别的, 灵活性差
问了下新浪的高鹏
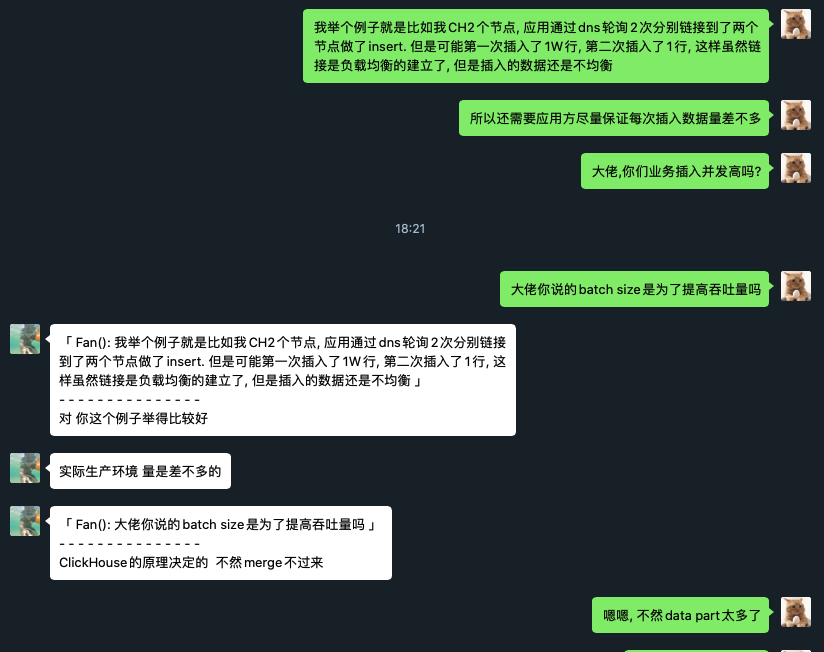
高鹏的回答总结一下就是:
- 新浪每天增量是千亿级的, INSERT并发和节点数应该比较高, 直接写某个节点的分布式表, 这个节点还需要建立N-1个连接(N是集群节点数)分发数据, 再有就是他说的第3点
- 通过负载均衡向本地表插入数据要控制尽量每次插入数据建立一次连接, 每个链接插入的数据量要差不多, batch size不能太小, 否则data part过多, merge不过来clickhouse会报错