Orchestrator Failover过程源码分析-II
书接上文Orchestrator Failover过程源码分析-I
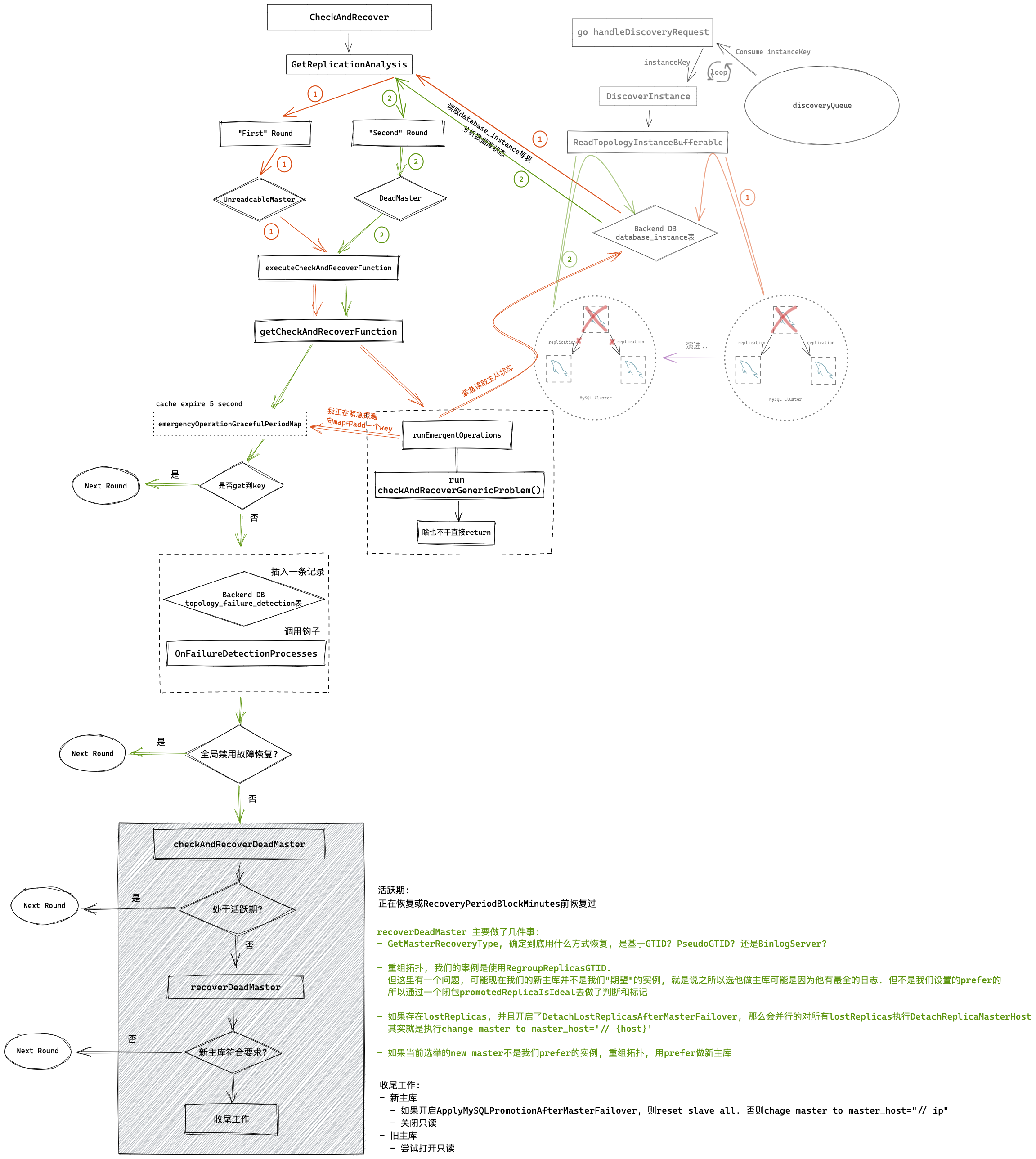
DeadMaster恢复流程
首先通过getCheckAndRecoverFunction获取”checkAndRecoverFunction”
1 | func getCheckAndRecoverFunction(analysisCode inst.AnalysisCode, analyzedInstanceKey *inst.InstanceKey) ( |
这里先判断isInEmergencyOperationGracefulPeriod
1 | func isInEmergencyOperationGracefulPeriod(instanceKey *inst.InstanceKey) bool { |
实际是尝试去emergencyOperationGracefulPeriodMap这个cache找有没有这个instance. 那么问题来了, 是谁在什么时候向这个cache放这个instance呢?
其实是在主库处于UnreachableMaster状态下, executeCheckAndRecoverFunction中调用runEmergentOperations时
1 | // executeCheckAndRecoverFunction will choose the correct check & recovery function based on analysis. |
可以看到, UnreachableMaster时, 会运行emergentlyReadTopologyInstance
1 | func runEmergentOperations(analysisEntry *inst.ReplicationAnalysis) { |
而在emergentlyReadTopologyInstance中会先尝试向emergencyReadTopologyInstanceMap中Add
1 | // Force a re-read of a topology instance; this is done because we need to substantiate a suspicion |
ReadTopologyInstance 实际调用 ReadTopologyInstanceBufferable
这个cache是在logic包init时创建的
1 | emergencyOperationGracefulPeriodMap = cache.New(time.Second*5, time.Millisecond*500) // 过期时间5s |
isInEmergencyOperationGracefulPeriod 如果返回true, 表示尚处于EmergentOperations运行窗口期内, 所以需要等
若返回false, 表示已经可以开始”恢复”了, 就会返回checkAndRecoverDeadMaster, 并且isActionableRecovery也为true
executeCheckAndRecoverFunction
1 | // It executes the function synchronuously |
对于本文场景, 当主库被认定处于DeadMaster状态后:
executeCheckAndRecoverFunction会先调用getCheckAndRecoverFunction获取:
- checkAndRecoverFunction: checkAndRecoverDeadMaster
- isActionableRecovery: true
然后检查是否”禁用”了全局故障恢复功能(如通过API disable-global-recoveries), 如果是, 则直接return
接下来, 开始执行checkAndRecoverFunction, 即checkAndRecoverDeadMaster
我们先不看checkAndRecoverDeadMaster具体逻辑, 继续往下看. 下面的代码就是根据checkAndRecoverFunction的执行情况(是否成功恢复), 调用对应的钩子, 最后将恢复结果return回去, 其实到这里, 本轮恢复就算做完了. 具体恢复是否成功, recoverTick也不关心. 具体如何恢复的, 还是要看checkAndRecoverFunction(本例中是checkAndRecoverDeadMaster)
关于钩子, 见:
OnFailureDetectionProcesses
PostUnsuccessfulFailoverProcesses
PostFailoverProcesses
checkAndRecoverDeadMaster
1 | // checkAndRecoverDeadMaster checks a given analysis, decides whether to take action, and possibly takes action |
checkAndRecoverDeadMaster 首先通过RecoverMasterClusterFilters再次判断这个实例是否可以进行自动故障恢复.
接着, 调用AttemptRecoveryRegistration检查这个实例是否最近刚刚被提升或该实例所处集群刚刚经历failover, 并且仍然处于活动期.
就是说刚Failover没多久又Failover不行, 类似MHA 8小时限制
活动期的时间由RecoveryPeriodBlockMinutes控制, 默认1小时. 也是在recoveryTick启动协程时会去清理in_active_period标记(update为0)
如果一切没问题, 会向数据库topology_recovery插入一条记录, 并new一个topologyRecovery结构体返回. 否则 topologyRecovery 是 nil
以上检查都没问题的话, 就正式开始执行恢复, 调用recoverDeadMaster.
我们先不看recoverDeadMaster代码, 继续往后看.
recoverDeadMaster最重要的是会返回promotedReplica, 即选举出来的新主库
代码运行到这里时, 可能已经选举出了new master, 即promotedReplica. 随后会运行overrideMasterPromotion函数
这个函数补充了一些判断条件, 判断这个promotedReplica是不是可以做new master
主要就是这几个参数:
- PreventCrossDataCenterMasterFailover
- PreventCrossRegionMasterFailover
- FailMasterPromotionOnLagMinutes
- FailMasterPromotionIfSQLThreadNotUpToDate
- DelayMasterPromotionIfSQLThreadNotUpToDate
以上任意一个判断有问题, 都会终止后续恢复动作, 直接return
最后, checkAndRecoverDeadMaster会对new master和old master做一些收尾工作, 如:
- 如果ApplyMySQLPromotionAfterMasterFailover为true, 则会在新主库执行 reset slave all 和set read_only=0, 否则走MasterFailoverDetachReplicaMasterHost逻辑
- 尝试连接旧主库打开只读
至此, 恢复成功完成.
具体的恢复逻辑, 还要看recoverDeadMaster
recoverDeadMaster
1 | // recoverDeadMaster recovers a dead master, complete logic inside |
recoverDeadMaster 主要做了几件事
- GetMasterRecoveryType, 确定到底用什么方式恢复, 是基于GTID? PseudoGTID? 还是BinlogServer?
- 重组拓扑, 我们的案例是使用RegroupReplicasGTID.
但这里有一个问题, 可能现在我们的新主库并不是我们”期望”的实例, 就是说之所以选他做主库可能是因为他有最全的日志. 但不是我们设置的prefer的
所以通过一个闭包promotedReplicaIsIdeal去做了判断和标记(通过postponedAll)
如果postponedAll=false, 则需要重组拓扑, 选择prefer的replica作为新主库postponedAll=true表是candidate就是”理想型”, 所有replica恢复可以并行异步执行
- 如果存在lostReplicas, 并且开启了DetachLostReplicasAfterMasterFailover, 那么会并行的对所有lostReplicas执行DetachReplicaMasterHost
其实就是执行change master to master_host=’// {host}’
- 如果当前选举的new master不是我们prefer的实例, 重组拓扑, 用prefer做新主库
recoverDeadMaster还是干了挺多事儿的, 尤其是RegroupReplicasGTID中的逻辑还是很复杂的. 本文就先不继续展开了, 要知后事如何, 请看Orchestrator Failover过程源码分析-III
初步流程总结