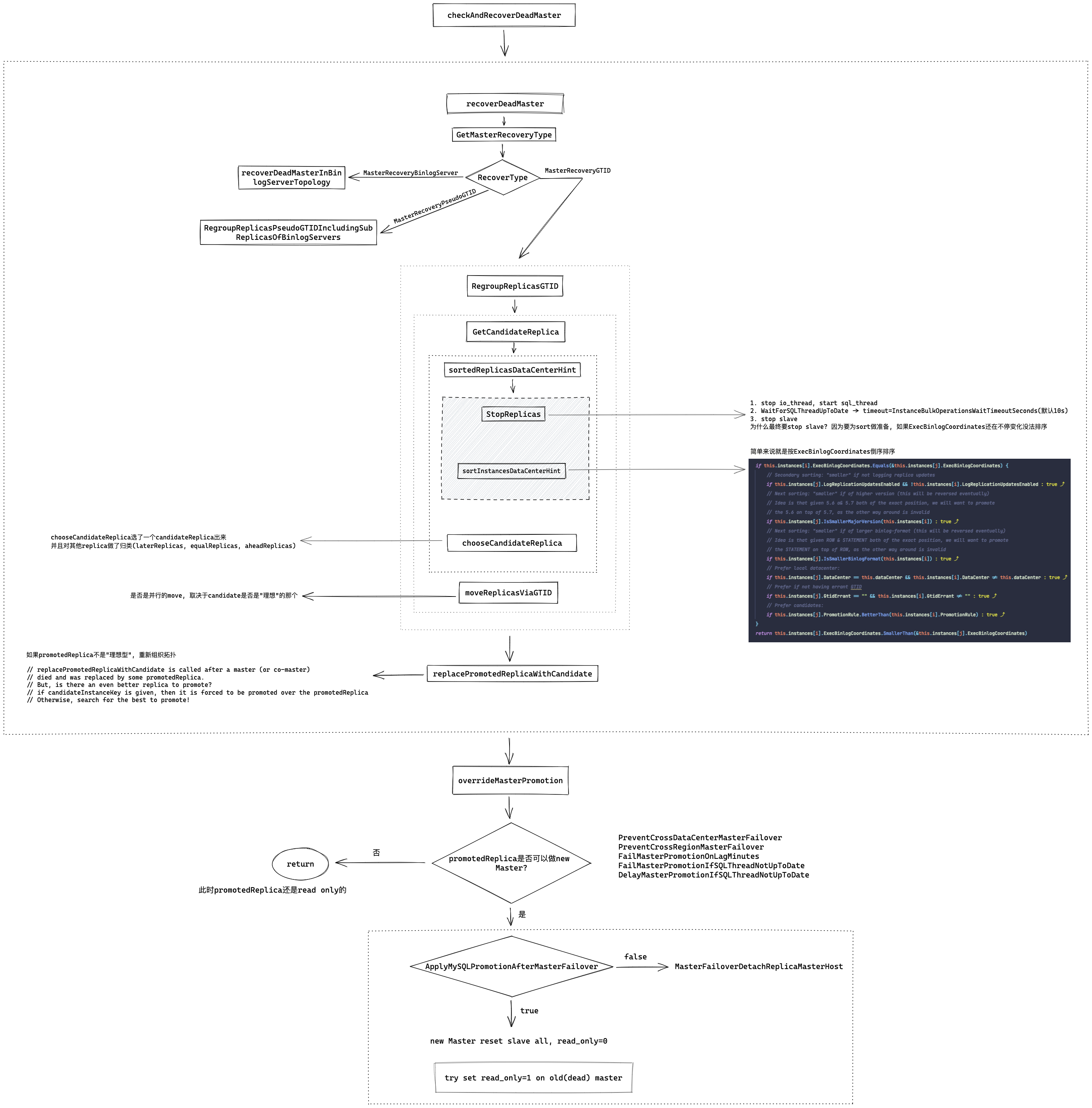
// RegroupReplicasGTID will choose a candidate replica of a given instance, and take its siblings using GTID funcRegroupReplicasGTID( masterKey *InstanceKey, // 实参传进来的是 挂掉的旧主库 returnReplicaEvenOnFailureToRegroup bool, // 实参传进来的是 true startReplicationOnCandidate bool, // 实参传进来的是 false onCandidateReplicaChosen func(*Instance), // 实参传进来的是 nil postponedFunctionsContainer *PostponedFunctionsContainer, postponeAllMatchOperations func(*Instance, bool)bool, // 实参传进来的是 promotedReplicaIsIdeal 函数 )
RegroupReplicasGTID will choose a candidate replica of a given instance, and take its siblings using GTID 英文简简单单一句话, 中文不知道咋翻译.. 我理解就是RegroupReplicasGTID会从目标实例(即DeadMaster)的从库中选出一个candidate出来, 然后提升他为新主库, 并接管所有的从库
// GetCandidateReplica chooses the best replica to promote given a (possibly dead) master funcGetCandidateReplica(masterKey *InstanceKey, forRematchPurposes bool) (*Instance, [](*Instance), [](*Instance), [](*Instance), [](*Instance), error) {
// sortedReplicas returns the list of replicas of some master, sorted by exec coordinates // (most up-to-date replica first). // This function assumes given `replicas` argument is indeed a list of instances all replicating // from the same master (the result of `getReplicasForSorting()` is appropriate) funcsortedReplicasDataCenterHint(replicas [](*Instance), stopReplicationMethod StopReplicationMethod, dataCenterHint string) [](*Instance) { iflen(replicas) <= 1 { // 如果只有一个从库, 直接返回 return replicas } // InstanceBulkOperationsWaitTimeoutSeconds 默认10s // 先 StopReplicationNicely 超时10s, 如果超时了也只是记了日志. 然后StopReplication // 然后 sortInstancesDataCenterHint. 这要看NewInstancesSorterByExec的Less方法如何实现. 简单说就是ExecBinlogCoordinates大的放前面, 如果ExecBinlogCoordinates一样, Datacenter和DeadMaster一样的放前面 replicas = StopReplicas(replicas, stopReplicationMethod, time.Duration(config.Config.InstanceBulkOperationsWaitTimeoutSeconds)*time.Second) replicas = RemoveNilInstances(replicas)
sortInstancesDataCenterHint(replicas, dataCenterHint) for _, replica := range replicas { log.Debugf("- sorted replica: %+v %+v", replica.Key, replica.ExecBinlogCoordinates) }
// sortInstances shuffles given list of instances according to some logic funcsortInstancesDataCenterHint(instances [](*Instance), dataCenterHint string) { sort.Sort(sort.Reverse(NewInstancesSorterByExec(instances, dataCenterHint))) }
type reverse struct { // This embedded Interface permits Reverse to use the methods of // another Interface implementation. Interface }> // Less returns the opposite of the embedded implementation's Less method. func(r reverse) Less(i, j int) bool { return r.Interface.Less(j, i) }> // Reverse returns the reverse order for data. funcReverse(data Interface) Interface { return &reverse{data} }
func(this *InstancesSorterByExec) Less(i, j int) bool { // Returning "true" in this function means [i] is "smaller" than [j], // which will lead to [j] be a better candidate for promotion // Sh*t happens. We just might get nil while attempting to discover/recover if this.instances[i] == nil { returnfalse } if this.instances[j] == nil { returntrue } if this.instances[i].ExecBinlogCoordinates.Equals(&this.instances[j].ExecBinlogCoordinates) { // Secondary sorting: "smaller" if not logging replica updates if this.instances[j].LogReplicationUpdatesEnabled && !this.instances[i].LogReplicationUpdatesEnabled { returntrue } // Next sorting: "smaller" if of higher version (this will be reversed eventually) // Idea is that given 5.6 a& 5.7 both of the exact position, we will want to promote // the 5.6 on top of 5.7, as the other way around is invalid if this.instances[j].IsSmallerMajorVersion(this.instances[i]) { returntrue } // Next sorting: "smaller" if of larger binlog-format (this will be reversed eventually) // Idea is that given ROW & STATEMENT both of the exact position, we will want to promote // the STATEMENT on top of ROW, as the other way around is invalid if this.instances[j].IsSmallerBinlogFormat(this.instances[i]) { returntrue } // Prefer local datacenter: if this.instances[j].DataCenter == this.dataCenter && this.instances[i].DataCenter != this.dataCenter { returntrue } // Prefer if not having errant GTID if this.instances[j].GtidErrant == "" && this.instances[i].GtidErrant != "" { returntrue } // Prefer candidates: if this.instances[j].PromotionRule.BetterThan(this.instances[i].PromotionRule) { returntrue } } return this.instances[i].ExecBinlogCoordinates.SmallerThan(&this.instances[j].ExecBinlogCoordinates) }
for _, replica := range replicas { replica := replica if isGenerallyValidAsCandidateReplica(replica) && // 做一些简单的检测, 比如IsLastCheckValid, LogBinEnabled, LogReplicationUpdatesEnabled(前三个都应该为true), IsBinlogServer(应为false) !IsBannedFromBeingCandidateReplica(replica) && // 是否被参数 PromotionIgnoreHostnameFilters 匹配, 希望不匹配 !IsSmallerMajorVersion(priorityMajorVersion, replica.MajorVersionString()) && // 希望 replica 版本 <= priorityMajorVersion. 更希望高版本做低版本从库. 那比如最常见版本是5.6, 然后有一个replica是5.7, 他是那个most up-to-date的从库, 到这里一比较, 他就不符合条件, 就被pass了 !IsSmallerBinlogFormat(priorityBinlogFormat, replica.Binlog_format) { // 希望比如priorityBinlogFormat row, 那replica是mixed或statement // this is the one candidateReplica = replica break } } // 不用想那么多, 以我们的场景, 不存在Major版本不同的, Binlog_format也都是row // 那只要这个从库没什么"毛病", 也没在PromotionIgnoreHostnameFilters中, 那基本上replicas[0]就是candidateReplica
// 如果上面的所有replica都不符合条件, candidateReplica就=nil, 就会进入这个if if candidateReplica == nil { // Unable to find a candidate that will master others. // Instead, pick a (single) replica which is not banned. for _, replica := range replicas { replica := replica if !IsBannedFromBeingCandidateReplica(replica) { // 选出第一个not banned的 // this is the one candidateReplica = replica break } } // 如果选出了一个 not banned if candidateReplica != nil { // 把candidateReplica从 replicas里移除 replicas = RemoveInstance(replicas, &candidateReplica.Key) } return candidateReplica, replicas, equalReplicas, laterReplicas, cannotReplicateReplicas, fmt.Errorf("chooseCandidateReplica: no candidate replica found") }
A naive approach would be to pick the most up-to-date replica, but that may not always be the right choice.
最新的副本可能没有必要的配置来充当其他副本的主节点(例如, binlog 格式、MySQL 版本控制、复制过滤器等). 一味地推广最新的副本可能会丢失副本容量 It may so happen that the most up-to-date replica will not have the necessary configuration to act as master to other replicas (e.g. binlog format, MySQL versioning, replication filters and more). By blindly promoting the most up-to-date replica one may lose replica capacity.
orchestrator 尝试提升将保留最多服务容量的副本. orchestrator attempts to promote a replica that will retain the most serving capacity.
// 如果chooseCandidateReplica走到 if candidateReplica == nil { ,就会进入这个if // Unable to find a candidate that will master others. // Instead, pick a (single) replica which is not banned. if err != nil { // returnReplicaEvenOnFailureToRegroup实参传进来的是 true if !returnReplicaEvenOnFailureToRegroup { candidateReplica = nil } return emptyReplicas, emptyReplicas, emptyReplicas, candidateReplica, err }
// equalReplicas 和 laterReplicas 都可以做candidateReplica的从库, 所以放到replicasToMove里 replicasToMove := append(equalReplicas, laterReplicas...) hasBestPromotionRule := true if candidateReplica != nil { // 迭代replicasToMove for _, replica := range replicasToMove { // 比较PromotionRule. 判断candidateReplica是不是用户prefer的 if replica.PromotionRule.BetterThan(candidateReplica.PromotionRule) { hasBestPromotionRule = false } } } moveGTIDFunc := func()error { log.Debugf("RegroupReplicasGTID: working on %d replicas", len(replicasToMove))
// moves a list of replicas under another instance via GTID, returning those replicas // that could not be moved (do not use GTID or had GTID errors) movedReplicas, unmovedReplicas, err, _ = moveReplicasViaGTID(replicasToMove, candidateReplica, postponedFunctionsContainer) unmovedReplicas = append(unmovedReplicas, aheadReplicas...) return log.Errore(err) }