
类MHA高可用方案存在的问题
MHA Generaly Available since 2011?
MHA在当时主要解决两个问题:
- 自动的数据补偿
- 自动的主从切换
还有两个重要的背景需要交代:
- 当时主要使用异步复制
- 当时还没有ProxySQL
所以当时基本使用MHA+VIP作为MySQL复制集的高可用方案.
不谈vip的脑裂问题, 这种架构的一个关键点在于, MHA是作为一个外部机制检测MySQL复制集状态, 并变更复制集拓扑, 变更后漂移vip, 也就是说MHA既控制了集群拓扑的变化, 又控制了app的访问路径(写通过vip)
脑裂
MHA+ProxySQL架构有一个问题:
MHA对MySQL复制集的监控检测逻辑中不包含ProxySQL, 因为MHA不知道用户在MySQL上层会构建什么样的中间件, 同时MHA变更集群拓扑后也并不会通知ProxySQL. 也就是说MHA和ProxySQL有可能会产生不同的”观点”
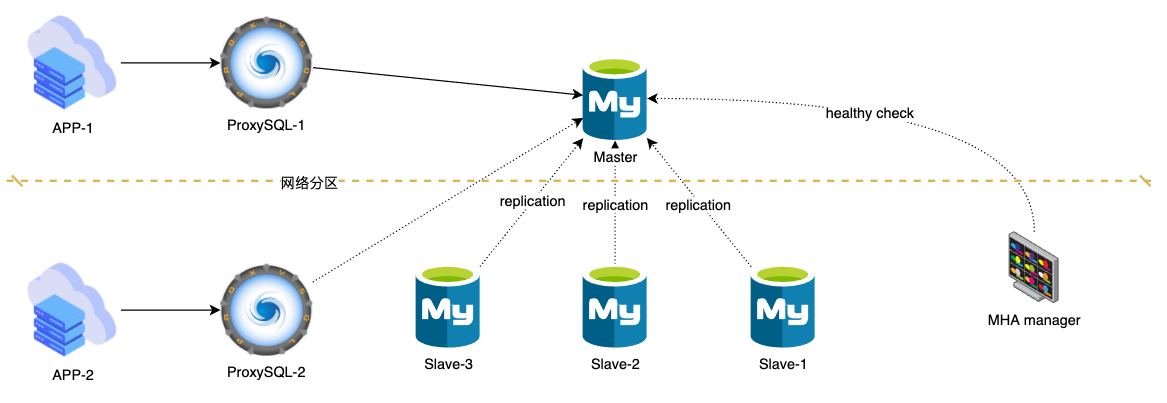
如上图场景
- APP-1, ProxySQL-1和主库在一个网络分区, 正在写入数据(异步复制, 或半同步超时不是无限大)
- APP-2, ProxySQL-2, 从库和MHA manager在一个网路分区, 无法连通主库
这种情况, MHA会Failover. Failover后变成如下拓扑
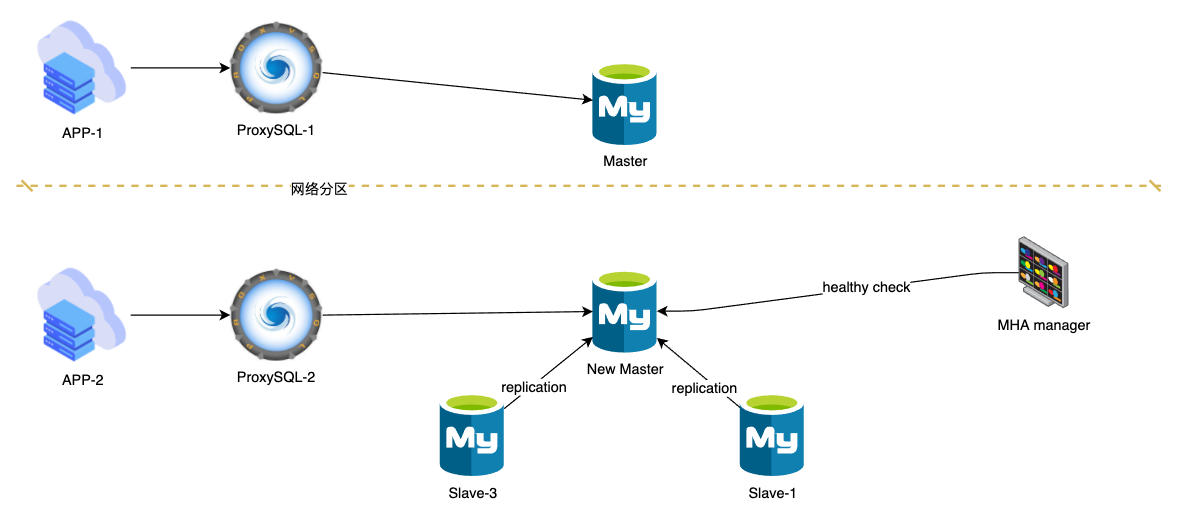
这就导致了脑裂(如果是半同步且超时无限大, 那么不会脑裂, 因为数据无法写入Master). 实际上如果在secondary_check_script中配置了ProxySQL地址
1 | secondary_check_script=masterha_secondary_check -s ProxySQL-1 -s ProxySQL-2 -s Slave-1 -s Slave-2 -s Slave-3 |
这样配置后, 在图-1的场景中, manager二次检测时无法ssh到ProxySQL-1, 二次检测脚本会以exit_code=2退出, 不会发生Failover, 就不会脑裂(如果是半同步且超时无限大, 那么不会脑裂, 因为数据无法写入Master).
2
3
4
5
# 0: master is not reachable from all monotoring servers
# 1: unknown errors
# 2: at least one of monitoring servers is not reachable from this script
# 3: master is reachable from at least one of monitoring servers
极端场景无法完成Failover
上文的场景就是一种极端场景. 在这种场景(图-1)下, 正确的做法是切断Master流量(关闭APP-1并不太现实, 因为实际可能不只一个应用, 关闭ProxySQL或Master都是可以的), 然后进行切换. 但这正是MHA无法做到的.
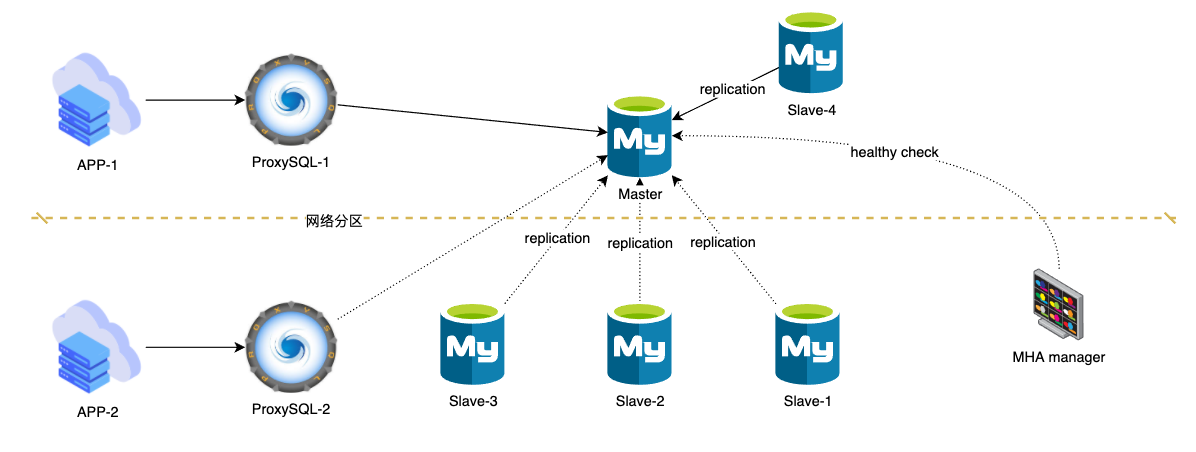
想象图-3场景, 使用半同步复制rpl_semi_sync_master_wait_for_slave_count=1
这种情况下, MHA仍然不会Failover(二次检测脚本-s中指定了slave-4), 那么按照正常逻辑, 应该Failover吗?
个人认为要看情况:
- 如果添加从库的速度很慢, 一旦Slave-4出现问题无法返回ack, Master将不能提供写入, 那么应该Failover, 将Slave1-3组成一个新的复制集, 一主两从, 两个从库出现异常的概率显然要小很多
- 如果添加从库的速度很快(备份集小, 自动化完善), 并且当时的场景不允许哪怕3-5秒的不可用(切换用时), 那么可以快速为Master添加一个从库Slave-5
为什么类MHA的高可用方案在这种情况下无法完成Failover?
ProxySQL是一个”伪集群”
ProxySQL集群目前只做到了配置同步, 成员之间并没有使用共识算法实现选举机制, 在图-1的场景中检查ProxySQL-1和ProxySQL-2的
runtime_mysql_servers, 你会看到这样的结果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21ProxySQL-1
admin 15:10:50 [(none)]> select * from runtime_mysql_servers;
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
| 10 | 172.16.120.10 | 3358 | 0 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | master for backup read |
| 11 | 172.16.120.10 | 3358 | 0 | ONLINE | 1 | 0 | 1000 | 0 | 0 | 0 | master for backup read |
| 11 | 172.16.120.12 | 3358 | 0 | SHUNNED | 1000 | 0 | 1000 | 120 | 0 | 0 | slave |
| 11 | 172.16.120.11 | 3358 | 0 | SHUNNED | 1000 | 0 | 1000 | 120 | 0 | 0 | slave |
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
ProxySQL-2
admin 15:10:14 [(none)]> select * from runtime_mysql_servers;
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
| hostgroup_id | hostname | port | gtid_port | status | weight | compression | max_connections | max_replication_lag | use_ssl | max_latency_ms | comment |
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
| 11 | 172.16.120.11 | 3358 | 0 | ONLINE | 1000 | 0 | 1000 | 120 | 0 | 0 | slave |
| 11 | 172.16.120.10 | 3358 | 0 | SHUNNED | 1 | 0 | 1000 | 0 | 0 | 0 | master for backup read |
| 11 | 172.16.120.12 | 3358 | 0 | ONLINE | 1000 | 0 | 1000 | 120 | 0 | 0 | slave |
+--------------+---------------+------+-----------+---------+--------+-------------+-----------------+---------------------+---------+----------------+------------------------+
3 rows in set (0.00 sec)如果ProxySQL集群有选举机制, 那么一个集群至少需要三个节点, 当一个节点意识到自己无法与大多数成员通信时, 它应当将自己置为不可用状态.
MHA manager单点
这和ProxySQL有一些类似的情况. 如果MHA也是一个集群, 并在MySQL复制集的每个节点部署一个node, 那么在图-1的场景中, Master节点上的MHA node应当意识到自己已经脱离了大多数成员, 它无法发起MySQL拓扑变更, 它要做应当是关闭Master(或打开read_only)
青云开源的Xenon
好像实现了类似的功能, 但我也不确定, 这个项目使用人数太少 https://github.com/radondb/xenon/issues/107
不过同样, xenon是使用vip为应用提供写入通道, 也就是说xenon控制了访问路径
Orchestrator不知道是否实现了这样的功能, 需要调研
MHA的检测逻辑不包含ProxySQL, 变更拓扑后也没有通知ProxySQL
MHA的检测机制和ProxySQL并不相同, 两者可能对拓扑情况有不同的判断. 应当改造二次检测脚本, 通过连接ProxySQL判断主库状态, 但即使这样做, 在图-1的场景中, manager会发现自己无法连接ProxySQL-1, 那么二次检测脚本应当以exit_code=2退出, 不会发生Failover, 所以这仍然无法解决极端场景不能Failover的问题.
Failover后, MHA应当主动变更ProxySQL中的配置
携程数据库高可用架构实践有类似描述
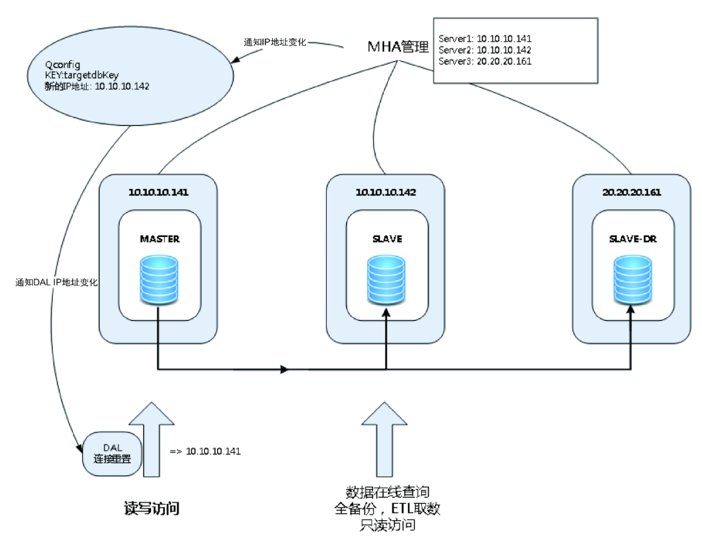
正确的做法与图-4类似, 在Failover后MHA应当将新的拓扑配置推送给”配置中心”, 保证应用使用新的配置连接数据库
美团也实现了类似的功能踩坑无数,美团点评高可用数据库架构演进
主从复制集并不是集群
即便从库都判定主库不可用, 也无能为力. 而假设是一个PXC或MGR集群(我们先不讨论这两者的问题), 图-1的场景会变成这样(以PXC为例):
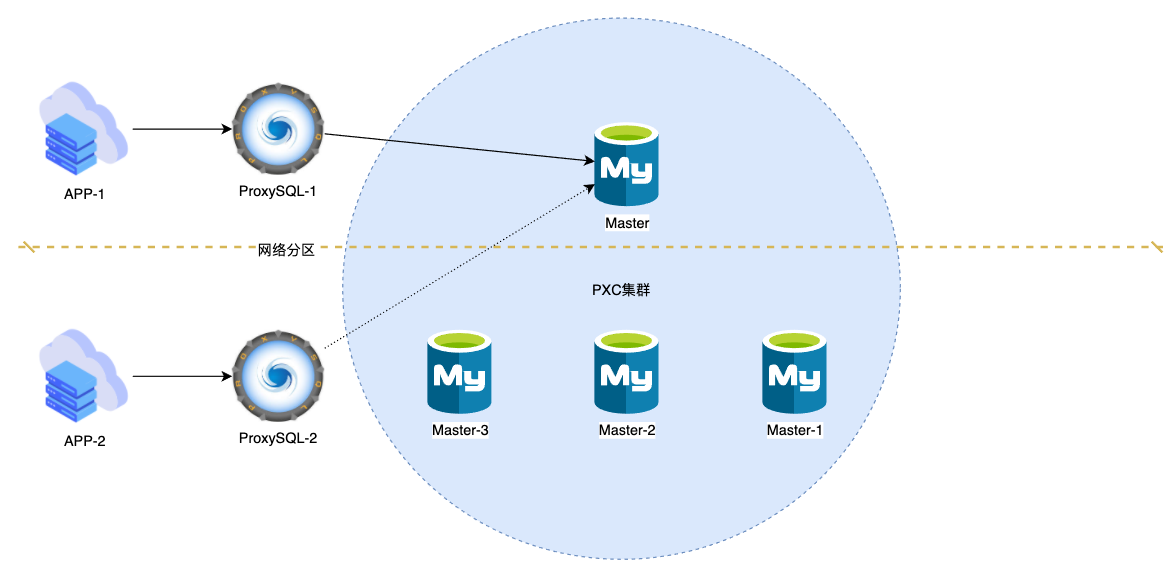
实际上图中PXC节点数量为偶数并不合理, 只是为了迎合图-1场景作对比
在PXC中, 所有节点都是主节点, 都可以写入, 只要提交成功就不会丢失数据
MGR也有多主模式, 如果是单主模式, 脱离集群的节点会将自己设为read_only
在图-5的情况下, Master会被踢出集群, 也就是说选举和拓扑变更是MySQL自己控制的, ProxySQL只需要被动接受就好了. (如果无法踢出Master呢? 那只能说遇到了内部bug, 任何软件都可能有bug, 包括MHA ProxySQL, Orchestrator等)
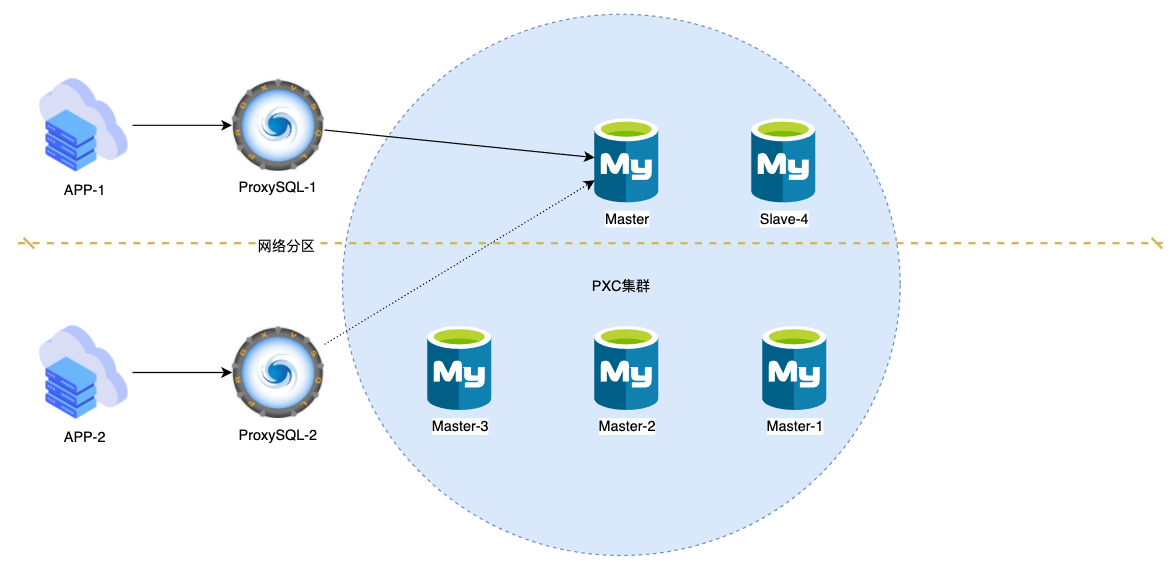
即便是下图的场景, PXC和MGR也能很好地完成选举, 剔除Master和Slave-4
总结
对于类MHA高可用方案, 需要进行改造以适应中间件.
对于MHA来说:
- 要改造masterha_secondary_check脚本, 在二次检测时连接ProxySQL进行主库探活. master_ip_failover也需要改造, 要在failover后删除ProxySQL runtime_mysql_server中原主信息并load
- 一定要将半同步超时设置无限大, 避免脑裂
如果放弃MHA, 无论选择Orchestrator, PXC亦或是MGR, 都是MySQL架构上的大变动, 需要长时间的技术调研和测试以及业务方的配合, 这三者任何一个都需要DBA花时间学习, 是否升级架构取决于我们面临的问题是不是最迫切需要解决的, 以及风险可控性(扎实的理论基础和完善的测试可以提高可控性).
那么选择其实就两种:
- 继续使用MHA或类MHA架构, 需要做二次开发适应ProxySQL
- 使用PXC或MGR这类”原生”集群方案, 需要实际数据论证当前业务是否可以做这样的架构调整.
个人认为两种都可以, 不过MGR必将是未来金融级高可用方案的事实标准(个人拙见, 据我所知网易,腾讯金融目前就是使用MGR,不过它们对源码做了修改, 这并非中小企业所具备的能力), 但目前仍需等待(发展只有4年), 而PXC已经发展8年了, 目前来看相比MGR更可靠(去哪儿网, 马蜂窝和之前的一些p2p企业都是用PXC), 但任何能保证强一致性的集群都必然会有性能损耗, 还要看业务是否可以接受.
如果用长远的眼光看, 调研并在一些边缘系统实践MGR是需要做的.
如CMDB, 明显的读多写少的系统, 美团点评基于MGR的CMDB高可用架构搭建之路