




masterha_manager: Command to run MHA Manager
MHA Manager can be started by executing masterha_manager command.
1 | # masterha_manager --conf=/etc/conf/masterha/app1.cnf |
masterha_manager takes below arguments.
prepare1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40sysbench /tmp/sysbench-master/src/lua/oltp_read_write.lua --mysql-user=root --mysql-password=mysql --mysql-port=3306 \
--mysql-socket=/data/mysql55/mysql.sock --mysql-host=localhost \
--mysql-db=sysbenchtest --tables=10 --table-size=5000000 --threads=30 \
--events=5000000 --report-interval=5 prepare
##--table-size=五百万,一个表五百万 10个表 五千万
##--threads=30 开30个线程并发prepare
Initializing worker threads...
Creating table 'sbtest6'...
Creating table 'sbtest4'...
Creating table 'sbtest5'...
Creating table 'sbtest10'...
Creating table 'sbtest8'...
Creating table 'sbtest3'...
Creating table 'sbtest9'...
Creating table 'sbtest1'...
Creating table 'sbtest2'...
Creating table 'sbtest7'...
Inserting 5000000 records into 'sbtest4'
Inserting 5000000 records into 'sbtest5'
Inserting 5000000 records into 'sbtest6'
Inserting 5000000 records into 'sbtest8'
Inserting 5000000 records into 'sbtest3'
Inserting 5000000 records into 'sbtest9'
Inserting 5000000 records into 'sbtest10'
Inserting 5000000 records into 'sbtest7'
Inserting 5000000 records into 'sbtest1'
Inserting 5000000 records into 'sbtest2'
Creating a secondary index on 'sbtest6'...
Creating a secondary index on 'sbtest9'...
Creating a secondary index on 'sbtest4'...
Creating a secondary index on 'sbtest8'...
Creating a secondary index on 'sbtest3'...
Creating a secondary index on 'sbtest7'...
Creating a secondary index on 'sbtest2'...
Creating a secondary index on 'sbtest1'...
Creating a secondary index on 'sbtest5'...
Creating a secondary index on 'sbtest10'...
1 | Naval Fate. |
该示例描述了可执行的naval_fate的界面,可以使用命令(ship,new,move等)的不同组合,选项(-h,–help,–speed =
示例使用方括号“[]”,圆括号“()”,管道“|” 和省略号“…”来描述可选的,必需的,相互排斥的和重复的元素. 一起,这些元素形成有效的使用模式,每个都以程序的名称naval_fate开头.
Below the usage patterns,有一个包含说明的选项列表. 它们描述一个选项是否具有短/长形式(-h,–help),选项是否具有参数(-speed =
在Usage:(不区分大小写) 关键字 间出现,并且显示的空了一行的部分 被解释为 usage pattern
在”Usage:”后出现的第一个单词被解释为程序的名字. 下面是一个最简单的示例,该示例没有任何命令行参数1
#### Usage: my_program
程序可以使用用于描述模式的各种元素列出几个模式:1
2
3
4
5
6Usage:
my_program command --option <argument>
my_program
my_program --another-option=<with-argument>
my_program (--either-that-option | <or-this-argument>)
my_program <repeating-argument> <repeating-argument>...
5.7.6以后参数gtid_mode可以动态修改
GTID_MODE:
OFF
彻底关闭GTID,如果关闭状态的备库接受到带GTID的事务,则复制中断
OFF_PERMISSIVE
可以认为是关闭GTID前的过渡阶段,主库在设置成该值后不再生成GTID,备库在接受到带GTID 和不带GTID的事务都可以容忍
主库在关闭GTID时,执行事务会产生一个Anonymous_Gtid事件,会在备库执行:
SET @@SESSION.GTID_NEXT= ‘ANONYMOUS’
备库在执行匿名事务时,就不会去尝试生成本地GTID了
ON_PERMISSIVE
可以认为是打开GTID前的过渡阶段,主库在设置成该值后会产生GTID,同时备库依然容忍带GTID和不带GTID的事务
ON
完全打开GTID,如果打开状态的备库接受到不带GTID的事务,则复制中断
准备工作
1.拓扑中的所有服务器都必须使用MySQL 5.7.6或更高版本. 除非拓扑中的所有服务器都使用此版本,否则无法在任何单个服务器上启用GTID事务.
2.所有服务器都将gtid_mode设置为默认值OFF.
The following procedure can be paused at any time and later resumed where it was, or reversed by jumping to the corresponding step of Section 16.1.5.3, “Disabling GTID Transactions Online”, the online procedure to disable GTIDs. This makes the procedure fault-tolerant because any unrelated issues that may appear in the middle of the procedure can be handled as usual, and then the procedure continued where it was left off.
切换过程可以再任意时刻停止,并稍后继续执行
注意
在每一步执行完全完成后再执行下一步
M为主库,read write
S* 为从库,read only
现在要对M进行硬件维护,提升S1为主库,接管业务读写. M维护完成后作为从库,如下图
首先可以进行如下切换 (A)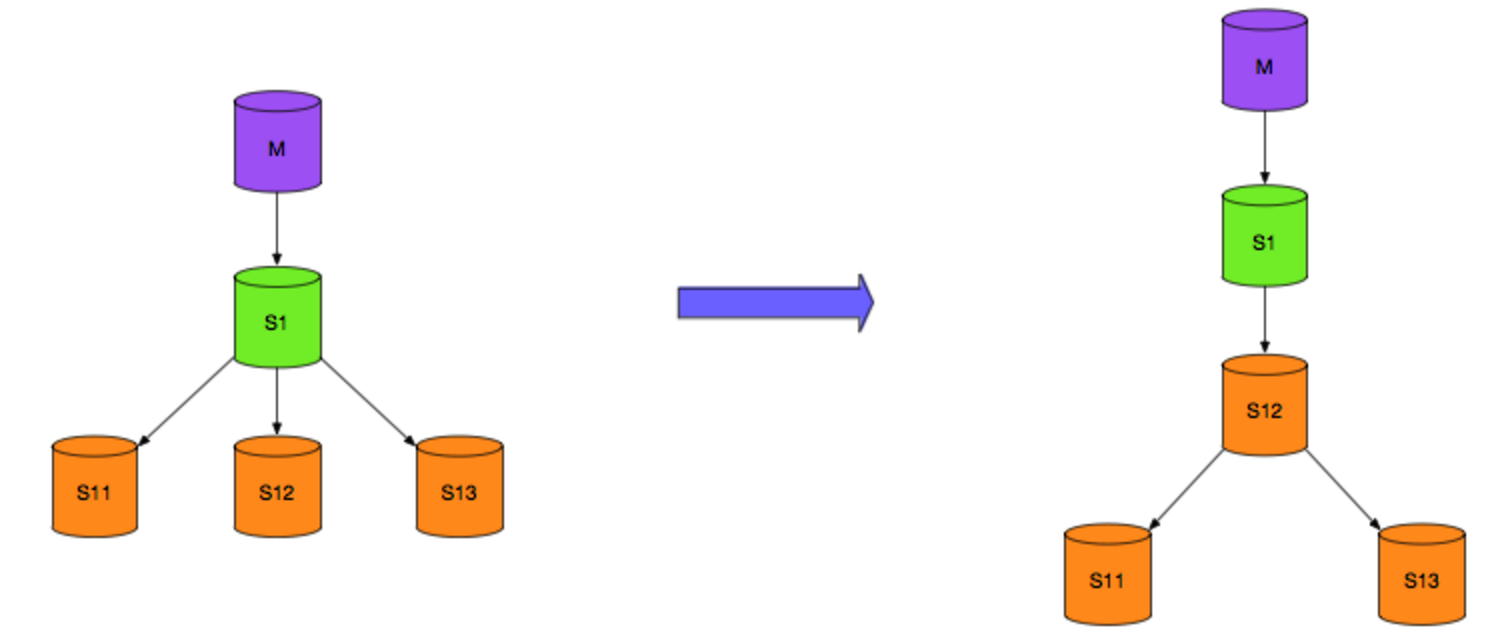
再进行如下切换(B)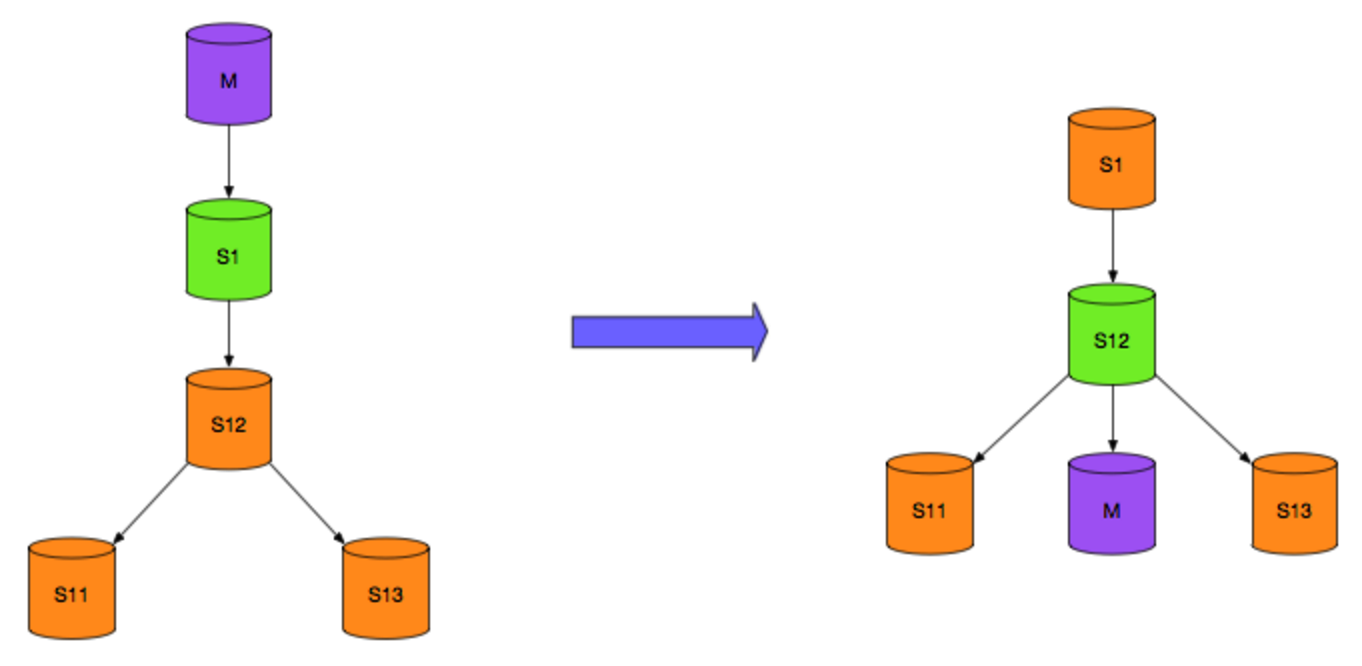
首先在S1制造”错误”1
2
3
4set session sql_log_bin=0;
create table t_error_maker(id int);
set session sql_log_bin=1;
drop table t_error_maker;
通过在session级别关闭写入binlog,建表,开启写入binlog,删表 制造异常, 当S11 S12 S13都执行到drop语句时,会报错停止sql_thread.
通过这种方式,可以让它们停止在同一个位置.
S121
show master status 获取File Position
S11 S131
2
3stop slave;
change master到S12上
start slave;
S121
2set global sql_slave_skip_counter=1;
start slave sql_thread;
M 停止业务写操作1
2
3set global read_only=on; 此时只有super权限用户能写入
set global super_read_only=on;禁止super权限用户写
#这里没有通过修改用户密码的方式是因为修改用户密码对已经连接上来的用户无效
等M S1 S12 跑一致后(File Position相同) 停S12 sql_thread, 将业务写入操作接入S1
最后M1
2
3
4set global read_only=off;
set global super_read_only=off;
change master 到S12
start slave
S121
start slave sql_thread;
以上步骤通过脚本完成的话,可以做到对业务造成很小的影响
脚本实例如下,注释掉了B步骤,因为需要配合切换业务写入操作
1 | cd /usr/local |
1 | cd src ; make ( you should have mysql_config available in $PATH) |
1 | [mysql@master ~]$ mysqladmin -umysql -p -S /data/mysqldata/3306/mysql.sock create tpcc10 |
支持的升级方法包括:
除非另有说明,否则支持以下升级路径:
升级之前,建议查看如下信息,并执行建议的步骤:
原文https://twindb.com/recover-after-drop-table-innodb_file_per_table-is-off/
详见https://github.com/chhabhaiya/undrop-for-innodb
误操作是不可避免的.错误的DROP DATABASE或DROP TABLE会摧毁重要的数据,更悲剧的是备份又不可用.
恢复方法取决于InnoDB是将所有数据保存在单个ibdata1中还是每个表都有自己的表空间.在这篇文章中,我们将考虑innodb_file_per_table = OFF的情况.此选项假定所有表都存储在通用文件中,通常位于/var/lib/mysql/ibdata1.
这里使用sakila库,假设我们误删除了actor表1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36mysql> SELECT * FROM actor LIMIT 10;
+----------+------------+--------------+---------------------+
| actor_id | first_name | last_name | last_update |
+----------+------------+--------------+---------------------+
| 1 | PENELOPE | GUINESS | 2006-02-15 04:34:33 |
| 2 | NICK | WAHLBERG | 2006-02-15 04:34:33 |
| 3 | ED | CHASE | 2006-02-15 04:34:33 |
| 4 | JENNIFER | DAVIS | 2006-02-15 04:34:33 |
| 5 | JOHNNY | LOLLOBRIGIDA | 2006-02-15 04:34:33 |
| 6 | BETTE | NICHOLSON | 2006-02-15 04:34:33 |
| 7 | GRACE | MOSTEL | 2006-02-15 04:34:33 |
| 8 | MATTHEW | JOHANSSON | 2006-02-15 04:34:33 |
| 9 | JOE | SWANK | 2006-02-15 04:34:33 |
| 10 | CHRISTIAN | GABLE | 2006-02-15 04:34:33 |
+----------+------------+--------------+---------------------+
10 rows in set (0.02 sec)
查看一下checksum
mysql> CHECKSUM TABLE actor;
+--------------+------------+
| Table | Checksum |
+--------------+------------+
| sakila.actor | 1702520518 |
+--------------+------------+
1 row in set (0.01 sec)
mysql> select count(*) from actor;
+----------+
| count(*) |
+----------+
| 200 |
+----------+
1 row in set (0.01 sec)
mysql> DROP TABLE actor;
Query OK, 0 rows affected (0.03 sec)