
如何做好MySQL的备份
物理备份还是逻辑备份?
其实物理备份和逻辑备份并没有好坏之分, 关键是要适合你的场景.
两种备份方式的备份工具有:
- 逻辑备份工具: [mysqldump, mysqlpump, mydumper, select into out file]
- 物理备份工具: [xtrabackup, TokuBackup, Tokudb-xtrabackup]
两种备份方式的对比如下
- 备份速度
物理备份比逻辑备份快吗? 不要想当然, 至少我的测试结果并不是这样 - 恢复速度
物理备份恢复实际就是mv操作(使用xtrabackup,在备份机做prepare), 而逻辑备份则是漫长的导入.
同机器 1.5T库, 逻辑备份大小151G, 做恢复需要27小时左右, 而物理备份恢复则完全取决于磁盘iops, 不用测也知道要比逻辑备份快很多 - 备份集大小
实际测试1T的库(大部分为InnoDB表), 逻辑备份集大小为46G, 而物理备份为255G
根据以上三点, 就可以选择备份方式了吗? 我认为不能. 还有一点是数据库服务器和备份服务器之间的网络情况, 和你期望的恢复时间是多久
选择什么样的备份取决于你期望的MTTR值和你的数据库体积
以目前我管理的数据库为例, 有三台备份服务器用于存储备份, 我们的库都是建在ECS上, 各种云都有.
如果数据库服务器和备服务器可以通过内网来传输备份, 那么大概100多G的备份要传2小时(大概100M/s), 如果你的库就是这么大, 那么无论你选择哪种方式备份, 都做不到快速恢复. 更别提很多数据库服务器和备份服务器还只能用外网传输备份了
- 如果可以严格控制数据库大小, 同时据库服务器和备服务器间使用万兆网卡传输备份, 那么无疑, 物理备份是最好的, 因为恢复快
- 如果无法控制数据库大小(不讨论为什么无法控制), 同时据库服务器和备服务器间网络垃圾, 那么任何一种备份方式都无法做到快速恢复, 此时优先考虑使用备份集较小的方式进行备份.
- 无论那种备份方式, 都不是用来做故障恢复的, 出故障了请做切换, 提前做好高可用, 这些备份是用来搭建从库, 恢复部分数据 和 做数据的最后一道保障用的.
选择好了备份方式, 如和用好/避免踩坑?
开源的东西, 没有什么是100%靠谱的, 就在刚才, Mydumper作者还处理了我提的一个issue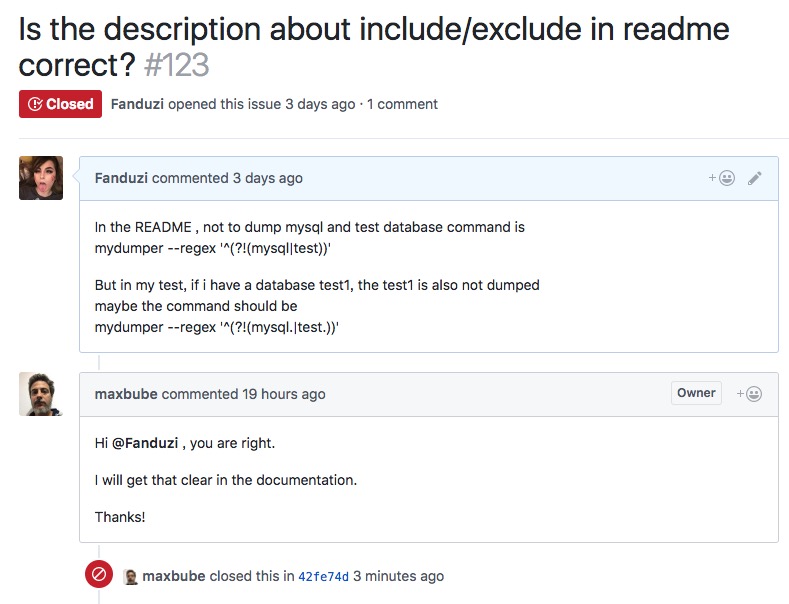
现在网上大部分的mydumper文档都是错的, 因为官方README就是错的, 并且他们眼高手低没有实际测试
无论使用哪种备份方式请先搞懂备份原理, 自己开General Log观察分析, 基本上这样已经能研究个八九十了, 然后可以看大神的文章:
mysqldump与innobackupex备份过程知多少(一)
mysqldump与innobackupex备份过程知多少(二)
mysqldump与innobackupex备份过程知多少(三)
mysqldump与innobackupex备份过程知多少(完结篇)
逻辑备份
深坑! mysqldump 不锁非事务表
如果你们数据库有很多MyISAM表, 那真的是不应该啊, 已经是被时代抛弃的引擎了
mysqldump在备份MyISAM表时, 是不锁DML的 ,也就是说如果备份期间对MyISAM表有DML操作的话, 那么整个备份集是不能保证一致性的, 详见mysqldump与mysqldump与innobackupex备份过程知多少(三)中的坑一
备份期间当心DDL
这个坑使用官方发型版本的MySQL数据库时, 无论使用xtrabackup还是mysqldump还是mydumper都有可能发生
具体就是使用START TRANSACTION /*!40100 WITH CONSISTENT SNAPSHOT */;语句显式开启一个事务之后,该事务执行select之前,该表被其他会话执行了DDL之后无法查询数据
详见mysqldump与mysqldump与innobackupex备份过程知多少(三)中的坑二
A会话
1 | root@localhost 10:52: [test1]> show create table fan; |
B会话 执行DDL语句增加一列
1 | root@localhost 10:53: [test1]> alter table fan add col1 varchar(10); |
A会话再去查询数据, 报错
1 | root@localhost 10:52: [test1]> select * from fan; |
Xtrabackup会抛出异常日志
1 | [FATAL] InnoDB: An optimized(without redo logging) DDLoperation has been performed. All modified pages may not have been flushed to the disk yet. |
而mysqldump和mydumper貌似不会? 忘了. 总之, 这会导致备份不完整.
Percona版本通过LOCK TABLES FOR BACKUP解决了这个问题
LOCK TABLES FOR BACKUP使用新的MDL锁类型来阻止更新非事务表和所有表的和DDL语句. 更具体地说,如果有一个活动的LOCK TABLES FOR BACKUP锁,所有DDL语句以及对MyISAM,CSV,MEMORY和ARCHIVE表的所有更新将被阻止,并在PERFORMANCE_SCHEMA或PROCESSLIST以Waiting for backup lock的状态显示. 针对所有表的SELECT查询和针对InnoDB,Blackhole和Federated表的INSERT / REPLACE / UPDATE / DELETE不受LOCK TABLES FOR BACKUP的影响。Blackhole表显然与备份无关,并且Federated表被逻辑和物理备份工具忽略
使用Percona版本时 mysqldump增加了--lock-for-backup选项, 而mydumper会自动查看have_backup_locks参数来判断是否可以使用LOCK TABLES FOR BACKUP锁
1 | if (!no_locks) { |
当心timestamp类型字段
SELECT INTO OUT FILE这货有什么用?
一个DELETE没有写where条件的酸爽你可曾体会?
你说, 我有binlog2sql大法
我说, 嘻嘻, 我们还在用Statement格式
悲剧的我, 还有一根稻草, 那就是SELECT INTO OUT FILE大法
假设你要执行下面这更新
1 | update important_db.important_table set col1='abc' where id<1000 |
那可得先
1 | select id,col1 from important_db.important_table where id<1000 into outfile '/tmp/fan.sql'; |
真的出了问题, 可以这样恢复
1 | cat fan.sql | awk '{print "update important_db.important_table set col1="$2," where id="$1";"}' > roll_back.sql |
TokuDB引擎表咋备份?
逻辑备份mydumper,mysqldump都可以, 后者无法保证非事务表一致性
物理备份, Xtrabackup不支持, TokuBackup没试过, 可以使用Tokudb-xtrabackup
Tokudb-xtrabackup安装
不过使用Tokudb-xtrabackup备份, 基本是你的Tokudb表多大,备份就是多大了, 你有1T的 tokudb表, 物理备出来基本就是1T了….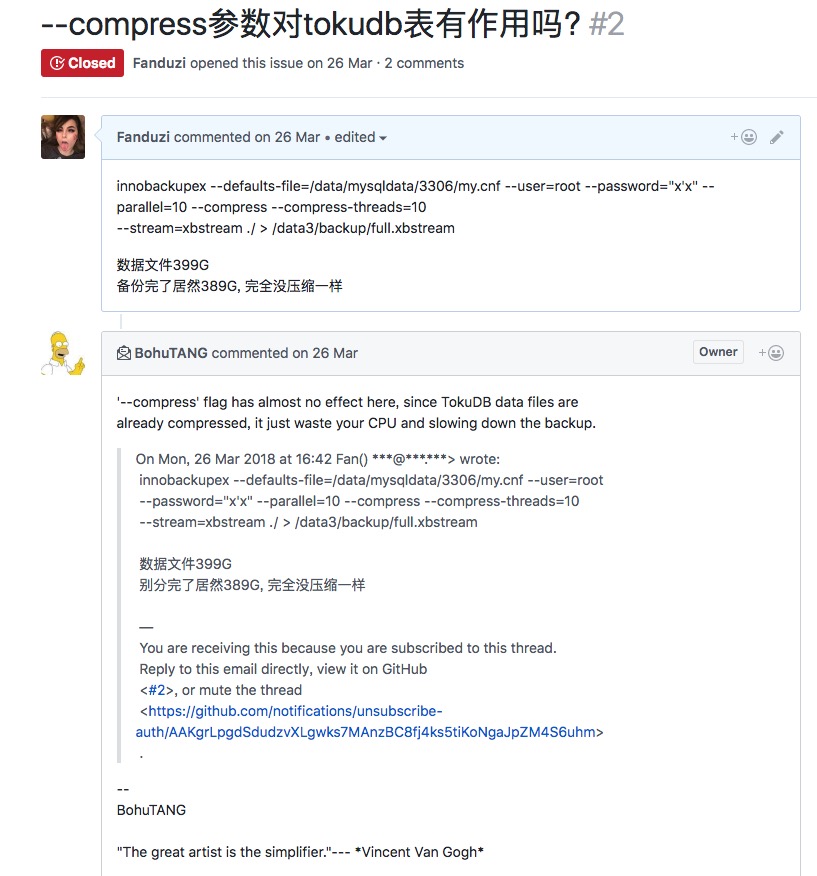
所以还是逻辑备份吧, 起码备份集小
重中之重, binlog备份
众所周知,Binlog中记录了数据库的所有变化, 通过备份 + 重演binlog, 可以将备份恢复到任意时间点
还在用rsync同步binlog吗? 你Out了
在5.7版本, mysqlbinlog命令增加一个新功能, 可以伪装成从库持续同步主库的binlog文件
详见Using mysqlbinlog to Back Up Binary Log Files
目前线上使用了我写的脚本做了一次封装Binlog_Server
废话这么多, 如何管理好你的备份?
数据库众多, 我接手前, 备份通过crontab调用shell脚本实现, 备份完成后再发送到备份机.
这样做的几点不足:
- 备份失败了没告警, 再写一个监控脚本监控日志输出? 太LOW
- 人脑真的记不住这么多备份与备份服务器的mapping关系, 每次都登录服务器去查吗? 效率太低
- 你能说出每个库备份多大吗? 备份用了多久? rsync用了多久? 这些指标异常能反应出什么问题
- 备份需要定期校验可用性, 手工校验费时费力
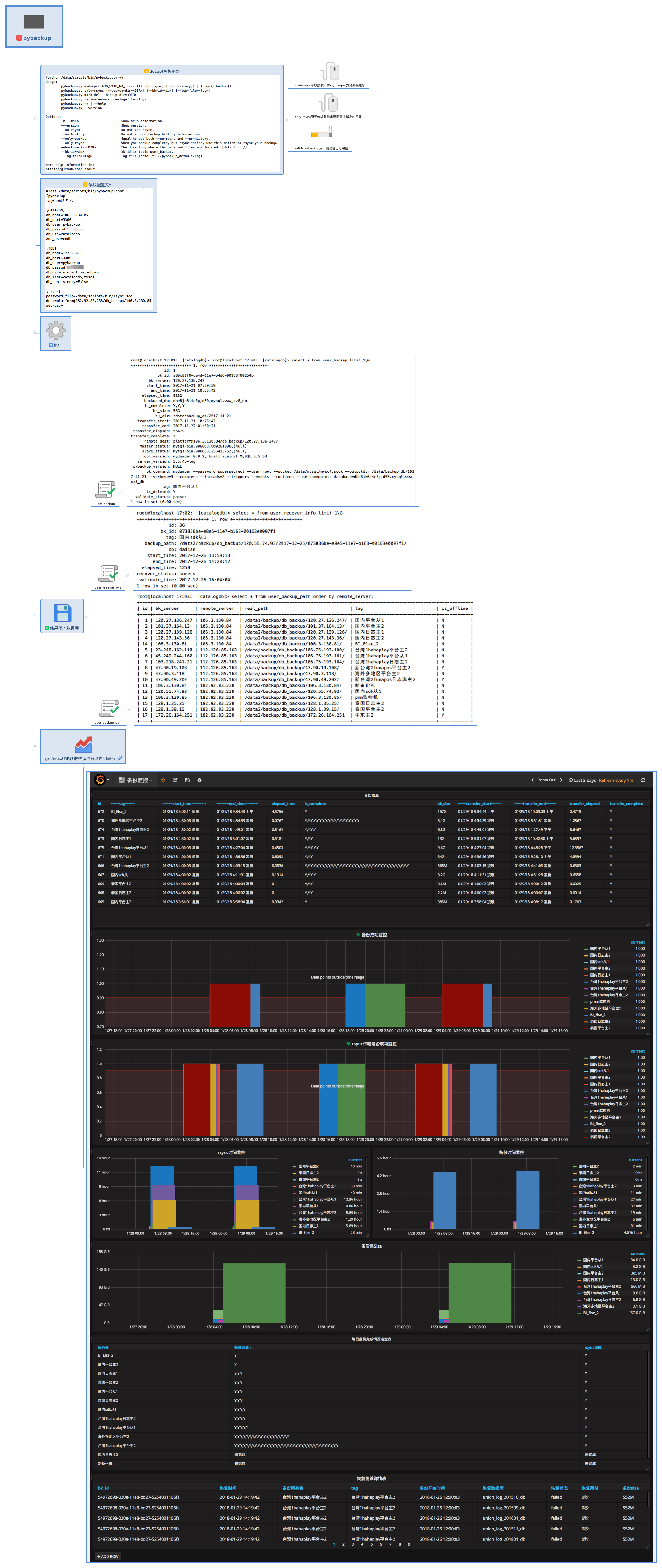
基于以上原因, 我做了改进, 编写了一个备份工具pybackup
pybackup源自于对线上备份脚本的改进和对备份情况的监控需求.
原本生产库的备份是通过shell脚本调用mydumper,之后再将备份通过rsync传输到备份机.
想要获取备份状态,时间,rsync传输时间等信息只能通过解析日志.
pybackup由python编写,调用mydumper和rsync,将备份信息存入数据库中,后期可以通过grafana图形化展示和监控备份
pybackup 提供了validate-backup命令 ,目前我再备份服务器上都安装了MySQL, 通过定时任务, pybackup会从catalog元数据中获取需要进行校验的备份自动校验备份
备份信息一览无遗
1 | root@localhost 23:49: [catalogdb]> select * from user_backup where tag='BI_Dota_2' order by id desc limit 1\G |
备份在哪一查就知道
1 | root@localhost 23:51: [catalogdb]> select * from user_backup_path; |
恢复用时, 心里有数
1 | root@localhost 23:52: [catalogdb]> select * from user_recover_info limit 1\G |
pybackup还需要完善, 比如对于备份校验的改进, 并且目前也没有做对xtrabackup的支持
2018.04.27 想了下可能应该恢复完成后, 首先去做源库的从库, 同步之后看有没有报错, 再完善点, 则是要做pt-table-checksum校验, 最近没时间, 后面再做吧
我们如何备份?大拿如何备份?
说了这么多, 那么我们现在是如何备份的呢? 目前线上用pybackup调用mydumper, 相比xtrabackup备份集小, 相比mysqldump一致性更有保证, 速度更快(mydumper可以并发,mysqldump只能单线程)
参加过一次技术大会, 印象中Facebook 是使用mysqldump备份的, 为什么? 这里要说道一下
Facebook有五个足球场大的机房?(可能记错了) , 总之数据库众多, 他们更在意备份集得大小(高可用玩的6, 存储要钱啊)
Facebook 的DBA严格限制单个数据库的大小为200G, 这样mysqldump备份时间快, 同时易于管理. Facebook DBA改进了备份方案, 他们大致是周一一个mysqldump全备, 之后每天备份binlog, 并分析binlog对其进行合并压缩
举个例子:
- 周一建了一个表t1, 周二删掉了, 或者周一insert t2的数据A, 周二又delete掉了
那么对于恢复到周二的需求, 就可以将binlog日志就合并, 省略掉t1表相关的所有语句, 和对t2 insert delete A记录的日志, 通过处理的日志, 在备份上应用, 直接通过程序构造一份周二的备份
我只能说, 牛批!🐂🐂🐂