Read part 1
在上一篇关于物化视图的博文中, 我们介绍了一种构造ClickHouse物化视图的方法, 该视图使用SummingMergeTree 引擎计算总和和计数. SummingMergeTree可以为这两种类型的聚合使用普通的SQL语法. 我们还让物化视图定义自动为数据创建基础表(.inner表). 这两种技术都很快速, 但对生产系统有限制(都不太适用于生产环境).
在本篇文章中, 我们将展示如何在现有的表上创建一个具有一系列聚合类型的物化视图. 当您需要计算的不仅仅是简单的总和时, 此方法非常适合. 对于表中有大量正在插入的数据(针对Part 1)中的 POPULATE, 使用POPULATE会填充历史数据, 但这期间向原表中新插入数据会被忽略掉而不会写入物化视图中)或必须处理表结构变更的情况, 这也非常方便.
使用State函数和To Tables创建更灵活的物化视图 在线面的例子中, 我们将测量设备的读数. 让我们从表定义开始.
1 2 3 4 5 6 7 CREATE TABLE counter ( when DateTime DEFAULT now (), device UInt32, value Float32 ) ENGINE =MergeTree PARTITION BY toYYYYMM(when )ORDER BY (device, when )
接下来, 我们添加足够的数据, 以使查询速度变得足够慢: 10个设备的10亿行合成数据. 注意: 如果您要尝试这些操作, 只需输入100万行即可. 无论数据量如何, 示例都可以工作.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 INSERT INTO counter SELECT toDateTime('2015-01-01 00:00:00' ) + toInt64(number / 10 ) AS when, (number % 10 ) + 1 AS device, ((device * 3 ) + (number / 10000 )) + ((rand() % 53 ) * 0.1 ) AS value FROM system.numbers LIMIT 1000000000 ↓ Progress: 1.00 billion rows, 8.00 GB (5.13 million rows/s., 41.07 MB/s.) Ok. 0 rows in set . Elapsed: 194.814 sec. Processed 1.00 billion rows, 8.00 GB (5.13 million rows/s., 41.07 MB/s.) SELECT count(*) FROM counter ┌────count()─┐ │ 1000000000 │ └────────────┘ SELECT * FROM counter LIMIT 1 ┌────────────────when─┬─device─┬─value─┐ │ 2015 -01 -01 00 :00 :00 │ 1 │ 3.6 │ └─────────────────────┴────────┴───────┘ [root@ bj2-all-clickhouse-test-02 11 :21 :30 /data/clickhouse/node2/data/duyalan] #du -sh counter/ 13 G counter/[root@ bj2-all-clickhouse-test-02 11 :21 :35 /data/clickhouse/node2/data/duyalan] #du -sh counter/ 12 G counter/[root@ bj2-all-clickhouse-test-02 11 :26 :04 /data/clickhouse/node2/data/duyalan] #du -sh counter/ 6.5 G counter/数据慢慢被压实
现在, 让我们看一下我们希望定期运行的示例查询. 它汇总了整个采样期间所有设备的所有数据. 在这种情况下, 这意味着表中3.25年的数据, 都是在2019年之前.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 SELECT device, count(*) AS count, max(value) AS max, min(value) AS min, avg(value) AS avg FROM counter GROUP BY device ORDER BY device ASC ┌─device─┬─────count─┬────────max─┬─────min─┬────────────────avg─┐ │ 1 │ 100000000 │ 100008.15 │ 3.077 │ 50005.599374785554 │ │ 2 │ 100000000 │ 100011.164 │ 6.0761 │ 50008.59962170133 │ │ 3 │ 100000000 │ 100014.1 │ 9.0022 │ 50011.599634214646 │ │ 4 │ 100000000 │ 100017.17 │ 12.0063 │ 50014.59989124005 │ │ 5 │ 100000000 │ 100020.164 │ 15.0384 │ 50017.59997032414 │ │ 6 │ 100000000 │ 100023.19 │ 18.1045 │ 50020.60019940771 │ │ 7 │ 100000000 │ 100026.055 │ 21.0566 │ 50023.60046194672 │ │ 8 │ 100000000 │ 100029.14 │ 24.0477 │ 50026.60002471252 │ │ 9 │ 100000000 │ 100032.17 │ 27.0218 │ 50029.60008679837 │ │ 10 │ 100000000 │ 100035.02 │ 30.0629 │ 50032.60051765903 │ └────────┴───────────┴────────────┴─────────┴────────────────────┘ 10 rows in set . Elapsed: 12.036 sec. Processed 1.00 billion rows, 8.00 GB (83.08 million rows/s., 664.67 MB/s.) bj2-all-clickhouse-test-02 :) select min(when),max(when) from counter; SELECT min(when), max(when) FROM counter ┌───────────min(when)─┬───────────max(when)─┐ │ 2015 -01 -01 00 :00 :00 │ 2018 -03 -03 09 :46 :39 │ └─────────────────────┴─────────────────────┘ 1 rows in set . Elapsed: 9.941 sec. Processed 1.00 billion rows, 4.00 GB (100.59 million rows/s., 402.36 MB/s.)
前面的查询很慢, 因为它必须读取表中的所有数据才能获得答案. 我们想要设计一个物化视图, 该视图读取的数据要少得多. 事实证明, 如果我们定义了一个每天汇总数据的视图, 则ClickHouse将正确地在整个时间间隔内汇总每天的数据.
与前面的简单示例(Part 1)不同, 我们将自己定义目标(.inner表)表. 这样做的好处是, 该表现在可见, 这使得加载数据以及进行模式迁移(表结构变更)更加容易. 下面是目标表的定义.
1 2 3 4 5 6 7 8 9 10 11 CREATE TABLE counter_daily ( day DateTime, device UInt32, count UInt64, max_value_state AggregateFunction(max , Float32), min_value_state AggregateFunction(min , Float32), avg_value_state AggregateFunction(avg , Float32) ) ENGINE = SummingMergeTree()PARTITION BY tuple()ORDER BY (device, day )
该表定义引入了一种新的数据类型, 称为AggregateFunction , 该数据类型保存部分聚合的数据(which holds partially aggregated data). 这个数据类型用于sum和count以外的聚合需求. 接下来, 我们创建相应的物化视图. 它从counter(源表)中选择数据, 并使用CREATE语句中的特殊TO语法将数据发送到counter_daily(目标表). 该表有聚合函数, SELECT语句有与之相匹配的函数, 如’ maxState ‘. 我们将在详细讨论聚合函数时讨论它们之间的关系.
1 2 3 4 5 6 7 8 9 10 11 12 13 CREATE MATERIALIZED VIEW counter_daily_mvTO counter_dailyAS SELECT toStartOfDay(when ) as day , device, count (*) as count , maxState(value ) AS max_value_state, minState(value ) AS min_value_state, avgState(value ) AS avg_value_state FROM counterWHERE when >= toDate('2019-01-01 00:00:00' )GROUP BY device, day ORDER BY device, day
TO关键字使我们可以指向目标表(存储物化视图数据的表, 在本例中即是counter_daily表), 但有一个缺点. ClickHouse不允许在TO中使用POPULATE关键字. 因此, 物化视图创建后没有任何数据. 我们将手动加载数据. 但是, 我们还将使用一个不错的技巧, 使我们可以避免在同时进行活动数据加载的情况下出现问题.
注意, 视图定义有一个WHERE子句. 这意味着2019年之前的任何数据都应该被忽略. 我们现在有了一种不丢失数据的方法来处理数据加载. 该视图将处理2019年到达的新数据. 同时, 我们可以通过插入加载2018年及之前的旧数据.
让我们通过将新数据加载到counter表中来演示它是如何工作的. 新数据将于2019年开始, 并将自动加载到视图中.
1 2 3 4 5 6 INSERT INTO counter SELECT toDateTime('2019-01-01 00:00:00' ) + toInt64(number /10 ) AS when , (number % 10 ) + 1 AS device, (device * 3 ) + (number / 10000 ) + (rand () % 53 ) * 0.1 AS value FROM system.numbers LIMIT 100000000
现在, 使用以下INSERT手动加载旧数据. 它会加载2018年及之前的所有数据.
1 2 3 4 5 6 7 8 9 10 11 12 INSERT INTO counter_dailySELECT toStartOfDay(when ) as day , device, count (*) AS count , maxState(value ) AS max_value_state, minState(value ) AS min_value_state, avgState(value ) AS avg_value_state FROM counterWHERE when < toDateTime('2019-01-01 00:00:00' )GROUP BY device, day ORDER BY device, day
我们终于可以从视图中查询数据了. 与目标表和物化化视图一样, ClickHouse使用专用语法从视图中进行选择.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 物化视图目标表 SELECT device, sum(count) AS count, maxMerge(max_value_state) AS max, minMerge(min_value_state) AS min, avgMerge(avg_value_state) AS avg FROM counter_daily GROUP BY device ORDER BY device ASC ┌─device─┬─────count─┬────────max─┬─────min─┬────────────────avg─┐ │ 1 │ 110000000 │ 100008.15 │ 3.051 │ 45914.69035234097 │ │ 2 │ 110000000 │ 100011.164 │ 6.0291 │ 45917.69056040798 │ │ 3 │ 110000000 │ 100014.1 │ 9.0022 │ 45920.690478928045 │ │ 4 │ 110000000 │ 100017.17 │ 12.0063 │ 45923.69086044358 │ │ 5 │ 110000000 │ 100020.164 │ 15.0114 │ 45926.69083122718 │ │ 6 │ 110000000 │ 100023.19 │ 18.0475 │ 45929.691088042426 │ │ 7 │ 110000000 │ 100026.055 │ 21.0566 │ 45932.69135215635 │ │ 8 │ 110000000 │ 100029.14 │ 24.0107 │ 45935.690912335944 │ │ 9 │ 110000000 │ 100032.17 │ 27.0218 │ 45938.69098338585 │ │ 10 │ 110000000 │ 100035.02 │ 30.0429 │ 45941.69140548378 │ └────────┴───────────┴────────────┴─────────┴────────────────────┘ 10 rows in set . Elapsed: 0.019 sec. Processed 13.69 thousand rows, 1.12 MB (729.14 thousand rows/s., 59.84 MB/s.) 物化视图 SELECT device, sum(count) AS count, maxMerge(max_value_state) AS max, minMerge(min_value_state) AS min, avgMerge(avg_value_state) AS avg FROM counter_daily_mv GROUP BY device ORDER BY device ASC ┌─device─┬─────count─┬────────max─┬─────min─┬────────────────avg─┐ │ 1 │ 110000000 │ 100008.15 │ 3.051 │ 45914.69035234097 │ │ 2 │ 110000000 │ 100011.164 │ 6.0291 │ 45917.69056040798 │ │ 3 │ 110000000 │ 100014.1 │ 9.0022 │ 45920.690478928045 │ │ 4 │ 110000000 │ 100017.17 │ 12.0063 │ 45923.69086044358 │ │ 5 │ 110000000 │ 100020.164 │ 15.0114 │ 45926.69083122718 │ │ 6 │ 110000000 │ 100023.19 │ 18.0475 │ 45929.691088042426 │ │ 7 │ 110000000 │ 100026.055 │ 21.0566 │ 45932.69135215635 │ │ 8 │ 110000000 │ 100029.14 │ 24.0107 │ 45935.690912335944 │ │ 9 │ 110000000 │ 100032.17 │ 27.0218 │ 45938.69098338585 │ │ 10 │ 110000000 │ 100035.02 │ 30.0429 │ 45941.69140548378 │ └────────┴───────────┴────────────┴─────────┴────────────────────┘ 10 rows in set . Elapsed: 0.003 sec. Processed 13.69 thousand rows, 1.12 MB (3.99 million rows/s., 327.87 MB/s.) 源表 SELECT device, count(*) AS count, max(value) AS max, min(value) AS min, avg(value) AS avg FROM counter GROUP BY device ORDER BY device ASC ┌─device─┬─────count─┬────────max─┬─────min─┬────────────────avg─┐ │ 1 │ 110000000 │ 100008.15 │ 3.051 │ 45914.69035234098 │ │ 2 │ 110000000 │ 100011.164 │ 6.0291 │ 45917.69056040798 │ │ 3 │ 110000000 │ 100014.1 │ 9.0022 │ 45920.69047892806 │ │ 4 │ 110000000 │ 100017.17 │ 12.0063 │ 45923.69086044358 │ │ 5 │ 110000000 │ 100020.164 │ 15.0114 │ 45926.690831227155 │ │ 6 │ 110000000 │ 100023.19 │ 18.0475 │ 45929.69108804243 │ │ 7 │ 110000000 │ 100026.055 │ 21.0566 │ 45932.691352156355 │ │ 8 │ 110000000 │ 100029.14 │ 24.0107 │ 45935.690912335944 │ │ 9 │ 110000000 │ 100032.17 │ 27.0218 │ 45938.69098338586 │ │ 10 │ 110000000 │ 100035.02 │ 30.0429 │ 45941.69140548378 │ └────────┴───────────┴────────────┴─────────┴────────────────────┘ 10 rows in set . Elapsed: 14.041 sec. Processed 1.10 billion rows, 8.80 GB (78.34 million rows/s., 626.72 MB/s.)
该查询正确总结了包括新插入数据在内的所有数据. 您可以通过在counter表上重新运行原始选择来检查计算结果是否一致. 不同之处在于, 物化视图返回数据的速度要快900倍(在我的测试中为4680倍). 由此可见, 学习一些新语法是值得的!!
此时, 我们可以回过头来解释一下在这一切的幕后发生了什么.
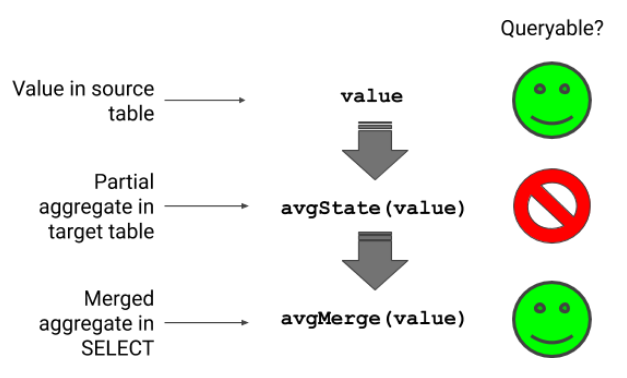
Aggregate Functions Aggregate functions类似于收集器(collectors), 允许ClickHouse从分布在多个parts上的数据构建聚合. 下面的图表显示了如何计算平均值. 我们从源表中的一个可选值开始. 物化视图使用avgState函数将数据转换为partial aggregate, avgState函数是一个内部结构. 最后, 在查询数据时, 应用avgMerge将partial aggregates的数据累加为最终的数字.
partial aggregate使物化视图能够处理分布在多个节点上的多个parts上的数据. 即使您更改了group by列, merge函数也可以正确地组装聚合. 仅仅结合简单的平均值是行不通的, 因为它们在将每个部分平均值加到总数时缺乏必要的权重. 这种行为有一个重要的后果(这段不会翻译, 原文: It would not work just to combine simple average values, because they would be lacking the weights necessary to scale each partial average as it added to the total. This behavior has an important consequence.).
还记得上面我们提到过, ClickHouse可以使用带有汇总的每日数据的物化视图来回答我们的示例查询吗?这是聚合函数工作的结果. 这意味着我们的daily视图还可以回答关于周、月、年或整个间隔的问题.
ClickHouse有点不寻常, 它直接以SQL语法公开了partial aggregates, 但是它们解决问题的方式非常强大. 当您设计实例化视图时, 请尝试使用每日汇总之类的技巧来解决单个视图中的多个问题. 单个视图可以回答很多问题.
Table Engines for Materialized Views ClickHouse有多个对物化视图有用的引擎. AggregatingMergeTree引擎只使用聚合函数. 如果您想做计数或求和, 您需要使用目标表中的AggregateFunction数据类型来定义它们. 您还需要在视图和select语句中使用state和merge函数. 例如, 要处理计数(count), 您需要在上面的示例中使用countState(count)和countMerge(count).
我们建议使用SummingMergeTree引擎在物化视图中进行聚合. 它可以很好地处理聚合函数. 它可以很好地处理聚合函数. 但是, 它会将它们隐藏起来以进行总数和计数, 这对于简单的案例来说非常方便. 在这种情况下, 它不会阻止您使用state和merge函数; 只是你没必要这么做. 同时, 它完成了AggregatingMergeTree的所有工作.
Schema Migration 在生产系统中, 数据库模式往往会发生变化, 特别是那些正在积极开发的系统. 当使用带有显式目标表的物化视图时, 可以相对容易地管理这些更改.
让我们举一个简单的例子. 假设counter表的名称更改为counter_replicated. 一旦应用了此更改, 物化视图将无法工作. 更糟糕的是, 这个错误将阻止对counter表的插入. 您可以按照以下方式处理更改.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 DROP TABLE counter_daily_mvRENAME TABLE counter TO counter_replicatedCREATE MATERIALIZED VIEW counter_daily_mvTO counter_dailyAS SELECT toStartOfDay(when ) as day , device, count (*) as count , maxState(value ) AS max_value_state, minState(value ) AS min_value_state, avgState(value ) AS avg_value_state FROM counter_replicatedGROUP BY device, day ORDER BY device, day
根据架构迁移中的实际步骤, 您可能必须处理更改物化视图定义时插入到源表的数据(这些数据未插入到物化视图中). 您可以使用过滤条件和手动加载来处理该问题, 如我们在主要示例中所示.
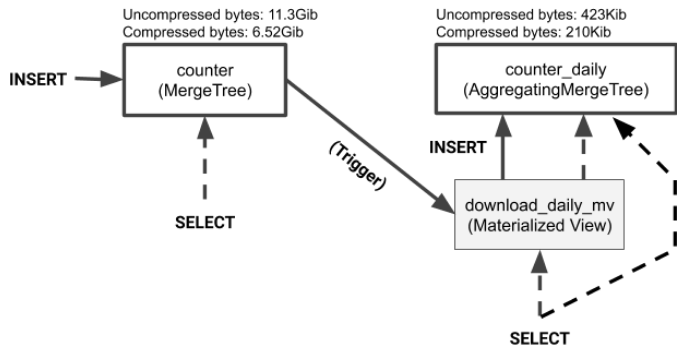
Materialized View Plumbing and Data Sizes 最后, 让我们再看看数据表和物化视图之间的关系. 目标表是一个普通表. 您可以从目标表或物化视图中选择数据. 没有区别. 此外, 如果您删除物化视图, 目标表扔将保留. 正如我们刚才所展示的, 您可以通过简单地删除和重新创建视图来对其进行模式更改. 如果需要更改目标表本身, 可以像对任何其他表一样运行ALTER table命令.
该图还显示了源表和目标表的数据大小. 物化视图通常远小于其汇总数据的表. 我们的示例就是这样的结果. 以下查询显示了此示例的大小差异.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 SELECT table , formatReadableSize(sum(data_compressed_bytes)) AS tc, formatReadableSize(sum(data_uncompressed_bytes)) AS tu, sum(data_compressed_bytes) / sum(data_uncompressed_bytes) AS ratio FROM system .columns WHERE database = currentDatabase()GROUP BY table ORDER BY table ASC ┌─table ────────────────────────────────┬─tc─────────┬─tu─────────┬──────────────ratio─┐ │ counter │ 7.14 GiB │ 12.29 GiB │ 0.5805970993939394 │ │ counter_daily │ 248.77 KiB │ 494.31 KiB │ 0.503261750004939 │ │ counter_daily_mv │ 0.00 B │ 0.00 B │ nan │ └──────────────────────────────────────┴────────────┴────────────┴────────────────────┘
如计算所示, 物化视图目标表大约比物化视图派生的源数据小3万倍. 这种差异极大地加快了查询速度. 如前面所示, 在使用来自物化视图的数据时, 测试查询的运行速度大约快了900x(我这里测试为4680x).
Wrap-up ClickHouse物化视图非常灵活, 这得益于强大的聚合功能以及源表、物化视图和目标表之间的简单关系. 物化视图允许显式目标表, 这是一个有用的特性, 可以简化模式迁移. 您还可以通过向视图选择定义添加筛选条件并手动加载丢失的数据来减少可能丢失的视图更新.
物化视图还有许多其他方法可以帮助转换数据. 我们已经描述了其中的一些问题, 比如 last point queries , 并且计划将来在这个博客上写一些其他的问题. 欲了解更多信息, 请查看我们最近的网络研讨会ClickHouse and the Magic of Materialized Views . 我们在这里介绍了几个用例示例.
最后, 如果你正在以你认为其他用户会感兴趣的方式使用物化视图, 写一篇文章或者在当地的ClickHouse会议上发言. 我们很乐意在Altinity的博客上发布社区用户的内容, 并在未来的聚会上寻找演讲者. 如果你有什么想与社区分享的, 请让我们知道.